一. 基础定义
1. Spaghetti codes
面条式代码(spaghetti code)是非结构化和难以维护的源代码的贬义词组,广泛地解释。 意大利面条代码可能由多种因素引起,例如易变的项目要求,缺乏编程风格规则以及能力或经验不足。
代码过度使用GOTO语句而不是结构化编程结构,从而导致错综复杂和不可维护的程序,通常称为意大利面条代码。 这样的代码有一个复杂和纠结的控制结构,导致程序流程在概念上就像一碗意大利面,扭曲和纠结。在美国国家标准局1980年出版的一本出版物中,用“意大利面条”这个词来描述那些“分散和分散的文件”的较旧的节目。 意大利面代码也可以描述一种反向模式,在这种模式下,面向对象是以程序风格编写的,比如创建方法过于冗长和混乱的类,或者抛弃面向对象的概念,比如多态。这种形式的意大利面代码的存在可能会显着降低系统的可理解性。
2. 花指令
花指令是,由设计者特别构思,希望使反汇编的时候出错,让破解者无法清楚正确地反汇编程序的内容,迷失方向。经典的是,目标位置是另一条指令的中间,这样在反汇编的时候便会出现混乱。花指令有可能利用各种指令:jmp, call, ret的一些堆栈技巧,位置运算,等等。
二. 分析前情况汇总
1. 解决面条式代码与花指令
在分析FinFisher时,第一个需要解决的混淆问题是清除垃圾指令和“意大利面条代码”,这是一种旨在混淆反汇编程序的技术。意大利面条代码通过添加连续的代码跳转,使得程序流难以阅读,因此得名。下面是FinFisher意大利面条式代码的一个示例。

接下来通过下面代码进行分析
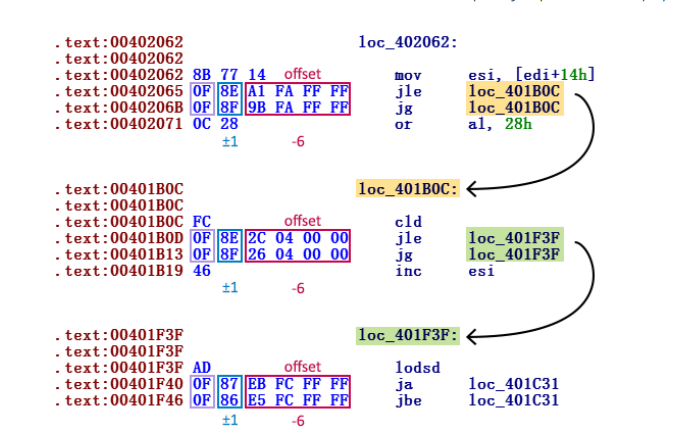
FinFisher使用了一种常见的反反汇编技术——通过将一个无条件跳转替换为两个互补的条件跳转来隐藏执行流。这些有条件的跳转都针对相同的位置,因此无论执行哪个跳转,都会产生相同的有效代码执行流。
条件跳转之后是垃圾字节。这是为了误导反汇编程序,反汇编程序通常不会识别它们是死代码,而是继续反汇编垃圾代码。
这个恶意软件的特殊之处在于它使用这种技术的方式。在我们分析的大多数其他恶意软件中,它只被使用了几次。然而,FinFisher在每条指令之后都使用这个技巧。
这种保护在欺骗反汇编程序时非常有效——代码的许多部分不能正确地反汇编。当然,在IDA Pro中不可能使用图形模式。我们的首要任务将是摆脱这种反反汇编保护。代码显然不是手动混淆的,而是使用自动化工具,我们可以观察到所有跳转对中的模式。
有两种不同类型的跳转对—32位偏移的近跳转和8位偏移的短跳转
两个条件近跳转(以dword作为跳转偏移量)的操作码都以0x0F字节开始;而第二个字节等于0x8*。在这两个跳转指令中只相差1位。这是因为x86操作码因为互补跳跃在数值上是连续的。例如,这种混淆方案总是将JE与JNE(0x0F 0x84 vs 0x0F 0x85操作码)配对,将JP与JNP(0x0F 0x8A vs 0x0F 0x8B操作码)配对,依此类推。
然后在这些操作码后面跟着一个32位的参数,指定到跳转目标的偏移量。由于两个指令的大小都是6字节,因此两个后续跳转中的偏移量相差正好6。(指令6字节的意思是OF 8E A1 FA FFFF是六个字节; fffffaa1与fffffa9b相差6字节,也就是保证jle与jg跳转到同一个地址)
下面的代码可以用来检测两个连续的跳转代码
def is_jump_near_pair(addr): jcc1 = Byte(addr+1) jcc2 = Byte(addr+7) # do they start like near conditional jumps? if Byte(addr) != 0x0F || Byte(addr+6) != 0x0F: return False # are there really 2 consequent near conditional jumps? if (jcc1 & 0xF0 != 0x80) || (jcc2 & 0xF0 != 0x80): return False # are the conditional jumps complementary? if abs(jcc1-jcc2) != 1: return False # do those 2 conditional jumps point to the same destination? dst1 = Dword(addr+2) dst2 = Dword(addr+8) if dst1-dst2 != 6: return False return True
短跳跃的解也是基于这种思想,只是常数不同。

短条件跳转的操作码等于0x7?,后跟一个字节–跳转偏移量。所以,当我们想要检测两个连续的、有条件的近跳时,我们必须寻找操作码:0x7?;偏移量;0x7 ? ± 1;偏移 -2。第一个操作码后面跟着一个字节,这两个字节在两个后续跳转中相差2(这也是两个指令的大小)。
例如,这段代码可以用来检测两个条件短跳转。
def is_jcc8(b): return b&0xF0 == 0x70 def is_jump_short_pair(addr): jcc1 = Byte(addr) jcc2 = Byte(addr+2) if not is_jcc8(jcc1) || not is_jcc8(jcc2): return False if abs(jcc2–jcc1) != 1: return False dst1 = Byte(addr+1) dst2 = Byte(addr+3) if dst1 – dst2 != 2: return False return True
在检测到其中一个条件跳转对之后,我们通过将第一个条件跳转补丁为无条件(对近跳转对使用0xE9操作码和并使用NOP指令修补其余的字节(0x90)。
def patch_jcc32(addr): PatchByte(addr, 0x90) PatchByte(addr+1, 0xE9) PatchWord(addr+6, 0x9090) PatchDword(addr+8,0x90909090) def patch_jcc8(addr): PatchByte(addr, 0xEB) PatchWord(addr+2, 0x9090)
除了这两种情况之外,在某些地方,跳跃对可能由短跳跃和近跳跃组成,而不是由同一类别的两个跳跃组成。但是,这只在FinFisher示例中的少数情况下发生,可以手动修复。
随着这些补丁的制作,IDA Pro开始“理解”新代码,并准备(或至少几乎准备好)创建一个图。在这种情况下,我们还需要做一个改进:附加tails,即分配节点目的地相同。
带有跳转指令的节点的位置图。为此,我们可以使用IDA Python函数append_func_tail。
克服反反汇编技巧的最后一步是固定函数定义。跳转后的指令仍然可能是push ebp,在这种情况下IDA Pro(不正确)将其视为函数的开始并创建一个新的函数定义。在这种情况下,我们必须删除函数定义,创建正确的定义并再次追加尾部。
以下是完整函数,针对短跳跃与近跳跃进行修改的代码:
def patch_jcc32(addr):#addr是一个字节 PatchByte(addr, 0x90) PatchByte(addr+1, 0xE9) PatchWord(addr+6, 0x9090) PatchDword(addr+8,0x90909090) def is_jump_near_pair(addr): jcc1 = Byte(addr+1) jcc2 = Byte(addr+7) if Byte(addr) != 0x0F or Byte(addr+6) != 0x0F: return False if (jcc1 & 0xF0 != 0x80) or (jcc2 & 0xF0 != 0x80): return False if abs(jcc1-jcc2) != 1: return False dst1 = Dword(addr+2) dst2 = Dword(addr+8) if dst1-dst2 != 6: print 'err' return False return True def patch_jcc8(addr): PatchByte(addr, 0xEB) PatchWord(addr+2, 0x9090) def is_jcc8(b): return b&0xF0 == 0x70 def is_jump_short_pair(addr): jcc1 = Byte(addr) jcc2 = Byte(addr+2) if not is_jcc8(jcc1) or not is_jcc8(jcc2): return False if abs(jcc2 - jcc1) != 1: return False dst1 = Byte(addr+1) dst2 = Byte(addr+3) if dst1 - dst2 != 2: return False return True import idc start = 0x0117C773 end = 0x0117D241 addr = start while addr <= end: near = is_jump_near_pair(addr) short = is_jump_short_pair(addr) print hex(addr),near,short if near == True: patch_jcc32(addr) print 'near_yes' if short == True: patch_jcc8(addr) print 'short_yes' addr = NextHead(addr,end)
2. 反反混淆技巧

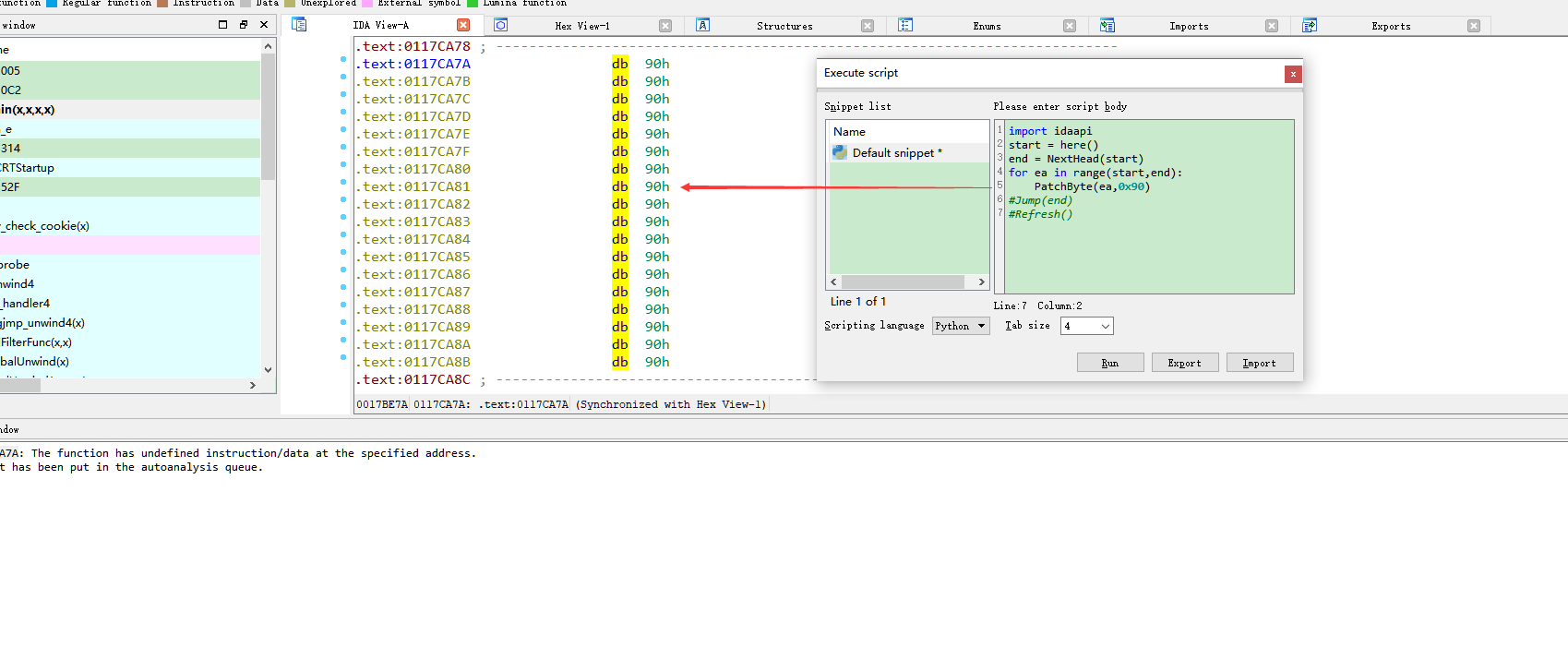
某些代码因为混淆,不能使用“空格”来将其图形化,解决方法是在0117c773处点击“p”来创建新的函数。
但是段代码被混淆,因为一些垃圾字节导致无法创建函数,所以就可以使用idapython将这块给修改成nop
首先按u,将这段数据的格式去掉,还原为“未定义”字节,接下来使用代码将其修改为nop

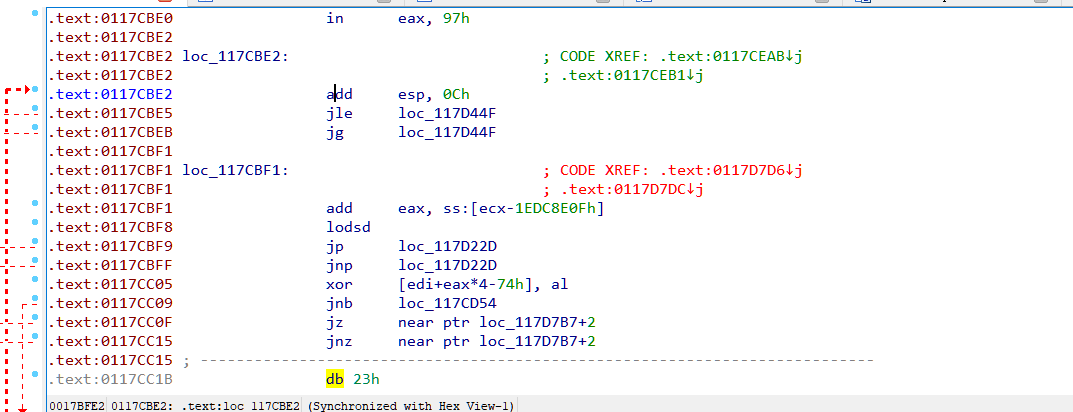
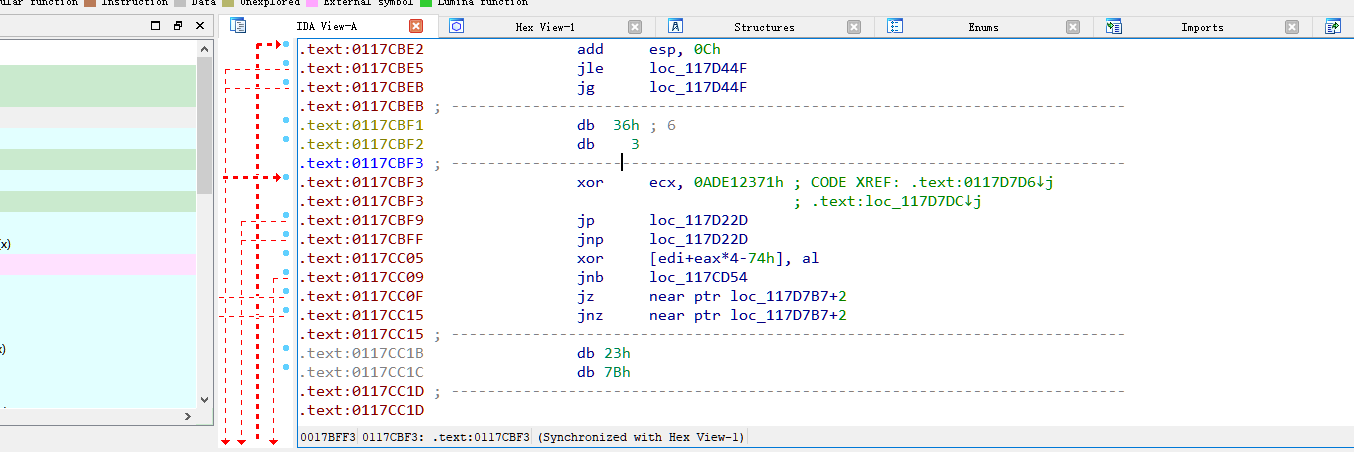
 也会遇到如下图,这种错误调用。0117d7dc处调用的是117cbf1+2,也即是117cbf3。但是ida给解析成117cbf1,所以第二张图引用就标红了,解决方法是:
也会遇到如下图,这种错误调用。0117d7dc处调用的是117cbf1+2,也即是117cbf3。但是ida给解析成117cbf1,所以第二张图引用就标红了,解决方法是:
在117cbf1处按“u”,去除格式。然后在117cbf3处按“c”,将接下来的指令解析成汇编。

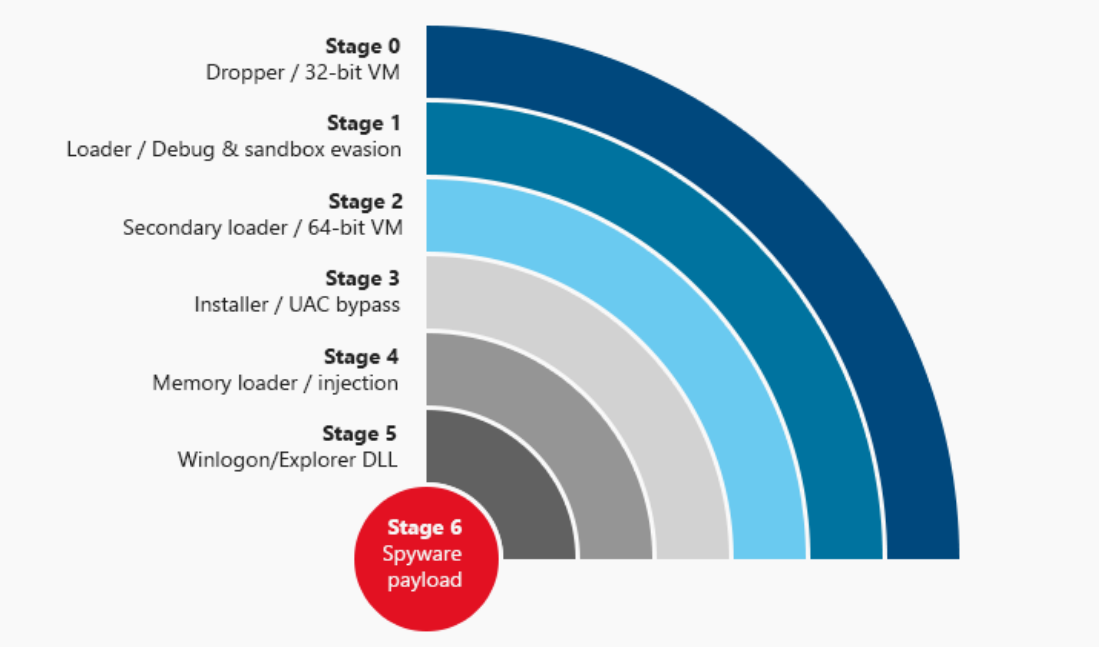
 3. 分析程序保护机制
3. 分析程序保护机制
删除垃圾指令显示了一个可读的代码块。这段代码首先分配两个内存块:一个全局1MB缓冲区和每个线程一个64 KB的缓冲区。大的第一个缓冲区用作多个并发线程的索引。从可移植可执行文件本身提取大块数据,并使用自定义的异或算法解密两次。我们确定该数据块包含一个操作码指令数组,准备由FinFisher a实现的定制虚拟机程序(从这里通常被称为“VM”)解释。以下是FinFisher多层保护机制。