
摘要
目前,针对高级持续性威胁(APT)样本检测的同源性判定方法种类较少,且大多数现有判定方案存在成本高、准确率低以及难以识别未知APT样本等问题。因此,我们通过整合深度学习和基因图谱提出了一种基于基因图谱的APT样本同源性判定系统。首先,我们从用户上传的样本中提取软件基因特征,并应用TF-IDF算法对提取的软件基因进行清洗。利用Word2Vec算法将所有基因向量化以构建基因样本向量。并且我们使用基于长短期记忆(LSTM)的分类器来检测APT攻击样本。最后,使用K近邻算法判定具有共享基因的APT样本的同源性。本文给出了该方案的详细构建过程,包括APT样本基因提取、清洗、聚类、样本检测以及同源性判定。实验验证表明,我们的模型优于现有方法,准确率达到95%、精确率达到94%、召回率达到95%。与之前的模型相比,我们方法的优越性明显。这些结果突显了我们模型的高效性和准确性,证实了其在网络安全领域重大应用的潜力。
**关键词**:APT样本、基因图谱、同源性判定
1. 引言
高级持续性威胁(APT)是一种采用高度隐蔽、有组织且具有威胁性的攻击方法,针对特定目标进行持续性网络攻击的攻击类型。在所有类型的网络攻击中,APT攻击的威胁等级最高且更难被检测到[1 – 3]。
2009年,一场名为“极光行动”的大规模APT攻击针对包括谷歌、奥多比系统公司和Rackspace等多家知名公司,旨在获取敏感的公司数据和用户账户信息。2010年,一种名为“震网”的网络武器瞄准了伊朗的核设施。该恶意软件是一种复杂的蠕虫,旨在渗透和破坏工业系统,特别是伊朗核计划中使用的西门子SIMATIC WinCC/PCS 7控制系统。据报道,震网破坏或摧毁了大约1000台离心机。另一个著名的例子是2016年美国民主党全国委员会(DNC)遭黑客攻击事件,其中APT28(奇幻熊)和APT29(舒适熊)参与窃取敏感数据、内部通信和电子邮件。根据奇安信的《全球高级持续性威胁(APT)2021年年度报告》[4],2021年中国境内大量IP地址与数十个境外APT组织产生高风险通信,且其数量和危害正以惊人的速度增长。APT对中国政府部门、医疗卫生部门以及高科技企业的攻击尤为突出。
面对APT攻击的爆发式增长,APT检测和溯源研究受到越来越多的关注。尽管许多高校、研究机构和企业组织已提出各种应对措施,但新型APT攻击不断涌现,加壳、混淆、沙箱逃逸等技术的出现使得传统检测方法面临严峻挑战,仅仅依靠人工对恶意代码样本进行识别和分类已变得不现实且效率低下。受此情况的驱动,我们专注于探索APT代码深层次的模式和特征,并利用机器学习、深度学习及其他相关技术高效准确地分析和检测未知APT样本。我们研究的主要贡献如下:
(1) 我们采用多方面的方法,整合了用于特征约简的TF – IDF、用于向量构建的Word2Vec、用于处理序列数据的三层LSTM模块以及用于同源性判定的KNN。
(2) 所提出的方法能够高效处理大型数据集,灵活适应APT的演变,并且在较少依赖标记数据的情况下保持较高的分类准确率。
(3) 实验验证表明我们的模型优于现有方法,准确率达到95%、精确率达到94%、召回率达到95%,通过与其他APT代码检测方法对比证明了我们方法的优越性。
2. 相关工作
恶意软件尤其是高级持续性威胁(APTs)的分析与分类已得到广泛研究,其方法从统计分析发展到复杂的机器学习和深度学习技术。本部分系统回顾了这些方法的发展进程,并突出了我们在该领域的创新贡献。
早期的APT分析方法侧重于通过统计方法进行特征提取。例如,研究人员在对APT源代码反编译后进行分解,并将特征按不同粒度级别分类[5]。他们利用词频(TF)对应用程序编程接口(APIs)进行优先级排序,说明了特征选择在分类任务中的重要性。然而,这些研究中使用的数据集(将在5.1节全面描述)通常范围有限,我们的工作旨在通过纳入更多样化且广泛的APT样本集来解决这一问题。
基于图的分析,如下载器图和功能依赖图,已被用于区分良性代码和恶意代码,Kwon等人[6]和Garbervetsky等人[7]分别使用这些图来分析下载模式和函数调用依赖关系。然而,APT的动态特性带来了挑战,因为变异可能改变结构模式。我们的研究引入了一种新颖的基因映射技术,增强了基于图的方法应对这些APT变异的鲁棒性。
在用于APT分类的机器学习领域,Rosenberg等人[8]展示了同源性判定,而Pascanu等人[9]和Miller等人[10]使用了递归神经网络和支持向量机(SVM)分类器。这些方法通常依赖大量的标记数据,而我们的方法通过应用K近邻(KNN)算法减少了这一要求,能够使用较少的标记样本进行有效分类。
在基于图的分析领域,Huang等人[11]提出了一种基于生物基因概念的多粒度融合特征用于二进制代码溯源。类似地,Zhao等人[12]引入了一种利用函数依赖图(FDG)子图作为基因的恶意软件同源性识别方法。虽然这些方法具有一定的洞察力,但存在局限性,例如选择关键APIs的复杂性和可扩展性问题。此外,恶意软件变异导致的结构变化以及FDGs的计算需求带来了重大挑战。我们的方法旨在解决这些局限性,在分析新的APT样本时提供一种可扩展的解决方案,降低与先前方法相关的过拟合风险。
深度学习在APT分类方面带来了重大进展。Zhao等人提出了一种基于纹理指纹的聚类方法来分析恶意代码的同源性[13]。该方法在不分析源代码的情况下分析二进制恶意程序,分析其图像纹理指纹信息并对指纹信息进行聚类。Sun等人提出了一种结合恶意代码分析、递归神经网络(RNN)和卷积神经网络(CNN)的恶意软件特征图像生成方法来识别恶意软件家族[14]。Zhang等人提出了一种深度神经网络(DNN)架构,应用多个门控卷积神经网络(Gated – CNNs)来提取应用程序编程接口(API)调用特征并执行动态恶意软件分析[15]。Li等人提出了一种基于RNN的恶意软件分类模型,通过使用长序列的API调用对恶意软件变体进行分类[16]。Chaganti等人提出了一种基于深度学习的双向门控循环单元 – 卷积神经网络(Bi – GRU – CNN)模型,通过分析ELF二进制文件字节序列来检测物联网(IoT)恶意软件并对恶意软件家族进行分类[17,18]。Do等人[19]提出了一种联合深度学习模型,利用多层感知机(MLP)、卷积神经网络(CNN)和长短期记忆(LSTM)网络通过网络流量分析进行APT攻击检测,在实验中达到了93%至98%的令人瞩目的准确率范围。然而,这些方法通常依赖大量的标记数据,而APT的标记数据稀缺,并且可能无法有效适应APT为逃避检测而不断演变的动态特性。
综上所述,我们的研究利用了现有方法的优势,同时引入新策略来克服其局限性。以下各节将更详细描述所提出的方法,这在APT的检测和分类方面迈出了重要的一步,改善了网络安全状况。
3. 系统设计
本章概述了APT同源性判定系统的设计,在其架构背景下详细阐述了其功能组件。基于该架构,系统包含了几个对APT同源性判定过程至关重要的关键功能。
3.1基因提取
软件基因是表示软件行为或功能的二进制代码段序列。在本系统中,软件基因是一个或多个基本块的组合。基本块是顺序执行的代码序列,以入口语句开始,以出口语句结束,仅通过入口进入且仅通过出口退出。如果一个基本块的最后一条指令是库函数调用(退出类除外),则该基本块与紧邻其物理地址的下一个基本块合并;当无法进一步合并时,所得的代码块就是软件基因。本系统的APT样本基因提取过程如表1所示。
通过上述步骤获得的基因是完整的汇编代码。为了使后续的基因清洗和相似度计算等操作更高效,本文使用操作码序列来表示基因,如图1所示。
3.2基因清洗
提取出的基因中还存在大量与恶意代码核心功能无关的基因,因此也有必要从软件基因中去除大量噪声,以更好地获取能够表征某一类APT特征的基因。本文在分类过程中使用TF-IDF(词频 – 逆文档频率)算法。该算法的主要思想是,如果一个词在一篇文章中出现的TF频率高,而在其他文章中很少出现,则该词或短语被认为具有良好的类别区分能力,适合用于分类。
在本系统中,TF-IDF算法用于选择在某一家族样本中频率高而在APT样本的其他家族样本中频率低的基因作为该家族的特征基因。对于特定APT样本中的基因x,其TF值的计算如公式(1)所示。

初始化阶段
function list ← r2.cmdj(’aflj’) :使用 radare2 工具的 aflj 命令获取可执行文件中所有的函数列表,并将其存储在 function list 变量中。
basic blocks ← empty list 和 genes ← empty list:分别初始化用于存储基本块和软件基因的空列表。
函数遍历循环
外层的 For each function in function list Do 循环用于逐个处理可执行文件中的每个函数。
r2.cmd(’s{}’.format(function)):在 radare2 中跳转到当前正在处理的函数。
basic blocks ← r2.cmd(’pdbj @@b’) :获取当前函数的所有基本块,并存储在 basic blocks 变量中。
基本块遍历循环
内层的 For each basic block in basic blocks Do 循环用于处理每个函数中的每个基本块。
每次开始处理一个新的基本块时,gene ← empty list 初始化一个空列表来存储当前软件基因。
再通过一个内层循环 For each code in basic block Do 逐个检查基本块中的每条代码。
如果代码是库函数调用(If code is a library function call Then),则将该代码添加到当前基因列表 gene 中,并将当前基因添加到总的基因集合 genes 中,然后重置 gene 为空列表,用于构建下一个可能的基因。
如果不是库函数调用,则直接将代码添加到当前基因列表 gene 中。
在处理完一个基本块中的所有代码后,无论最后一个基因列表 gene 是否为空,都将其添加到总的基因集合 genes 中,确保不遗漏任何可能的基因。
最终返回
Return genes:在处理完所有函数和其中的基本块后,返回提取到的所有软件基因集合 genes。
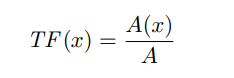
A(x)是包含基因x的该类APT样本的数量;A是该类APT样本的总数。
按公式(2)计算IDF值。
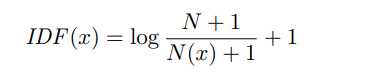
N 是 APT 类型的总数,N(x) 是给定家族样本集中包含基因 x 的 APT 类型的数量。
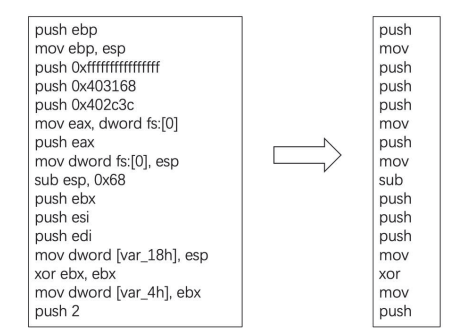
图1 软件基因图
通过求解公式(3)得到的TF-IDF值越高。

该基因越能表征那类APT特征。在本文中,找出每个样本的所有基因的TF-IDF值并进行排序。选择前400个基因作为该样本的特征基因。
3.3基因聚类
在APT样本分析中,功能相似的APT样本基因在某种程度上其序列形态也会相似,因此高度相似的基因可被视为本质上功能相同的基因,并可归为一类。基于软件基因的这一特性,本系统使用Word2Vec算法对操作码表示的基因序列进行向量化,进而使用余弦距离来计算两个向量的余弦相似度。
在使用Word2Vec获得词向量后,我们选择使用基因距离度量来比较两个基因的相似度,然后使用UPGMA(非加权组平均法)聚类算法对数据库中的所有基因进行聚类。UPGMA算法构建一个有根树(树状图),该树状图反映了结构中两两相似度矩阵(或相异度矩阵)的存在情况。在每一步中,将两个最接近的簇合并为一个更高层次的簇。任何大小为A和B的两个簇之间的距离是A中所有对象x与B中所有对象y的距离d(x,y)的平均值。因此,任意两个簇之间的距离由公式(4)定义:
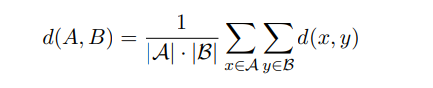
对于本系统而言,功能相似的基因往往具有相似的序列,所以将密切相关的基因分组在一起以降低维度。聚类算法依赖于距离的定义,这里通过Smith – Waterman算法来实现,该算法是一种局部序列比对方法,用于识别两个序列之间最相似的子序列。该算法对基因序列很有帮助,因为基因序列中可能只有特定部分相似。它具有很高的准确性,能适应基因序列中常见的插入或缺失情况,但它的计算量很大,尤其是对于长序列。在我们的系统中,预处理后的基因被归一化为较短的序列,以减轻聚类的计算成本。其主要设计思路如下:
给定基因序列A = a1, a2, …, an 和B = b1, b2, …, bm 的两种操作码表示形式,其中ai和bi均为操作码,使用一个从两个序列起始元素开始的矩阵记录由A的前i个元素组成的子序列和由B的前j个元素组成的子序列的最高得分,公式如公式(5)所示:
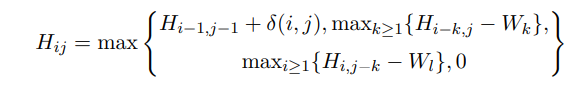
1 ≤ i ≤ n, 1 ≤ j ≤ m。Wk 是因长度为k的子序列不匹配而扣除的分数权重。δ(i, j) 是在序列中的ai和bj成功匹配时添加的分数值,当该值设置为1时,Hnm 恰好等于序列A和B的最长公共子序列的长度。序列A和序列B之间的距离dAB在方程(6)中定义。
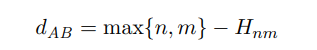

基于基因距离度量,本文采用优化的UPGMA聚类算法对相似基因进行聚类,然后将它们映射到一个样本向量中以实现降维,同时聚类使得各维度的相关性更低,满足机器学习对样本向量的要求。通过迭代执行UPGMA算法对高度相关的基因进行聚类,样本向量的维度逐渐降低,更适合经典机器学习算法进行处理。在本文中,聚类数设为256,从而得到256个簇。对于一个样本中的所有基因,检查其中一个簇中是否存在某个基因,如果存在,则将相应的向量位置设为1,否则设为0,从而构建一个长度为256的样本向量。这为后续机器学习算法提供了输入。
3.4检测
在构建样本向量之后,采用多层神经网络架构进行分类。首先,使用基于一维卷积的神经网络来处理输入向量。一维卷积层善于捕捉样本向量内的局部依赖关系和模式。
在卷积层之后,该架构集成了一个三层的长短期记忆(LSTM)模块,以有效对APT样本数据中固有的序列依赖关系进行建模。包括卷积层和三层LSTM模块在内的完整神经网络结构示意图如图2所示。
第一层LSTM有256个单元,用于处理从卷积层得到的初始特征表示,它捕捉数据内的初始时间关系。第一层LSTM的输出随后被送入第二层LSTM,第二层由128个单元组成。该层进一步细化时间特征,并从较低层次的表示中提取更复杂的模式。最后,具有64个单元的第三层LSTM接收第二层的输出,并继续进行时间特征提取过程。这种分层结构使网络能够在不同尺度和抽象层次上捕捉时间依赖关系。
第三层LSTM的输出随后被导向一个全连接层,该全连接层作为分类器。全连接层将LSTM所学习到的高级特征转化为长度为2的向量,代表给定样本是APT或非APT的概率。此输出用于实现APT检测器。
基于LSTM的APT检测器包含一系列基本的LSTM单元,这些单元构成了存储已处理APT样本行为概要的记忆存储层。图3展示了LSTM单元的架构。
在每个LSTM单元中,隐藏输出向量从LSTM单元传递到全连接(FC)层,并使用Softmax函数进行优化。以下递归方程(7)描述了这些LSTM单元的工作方式。
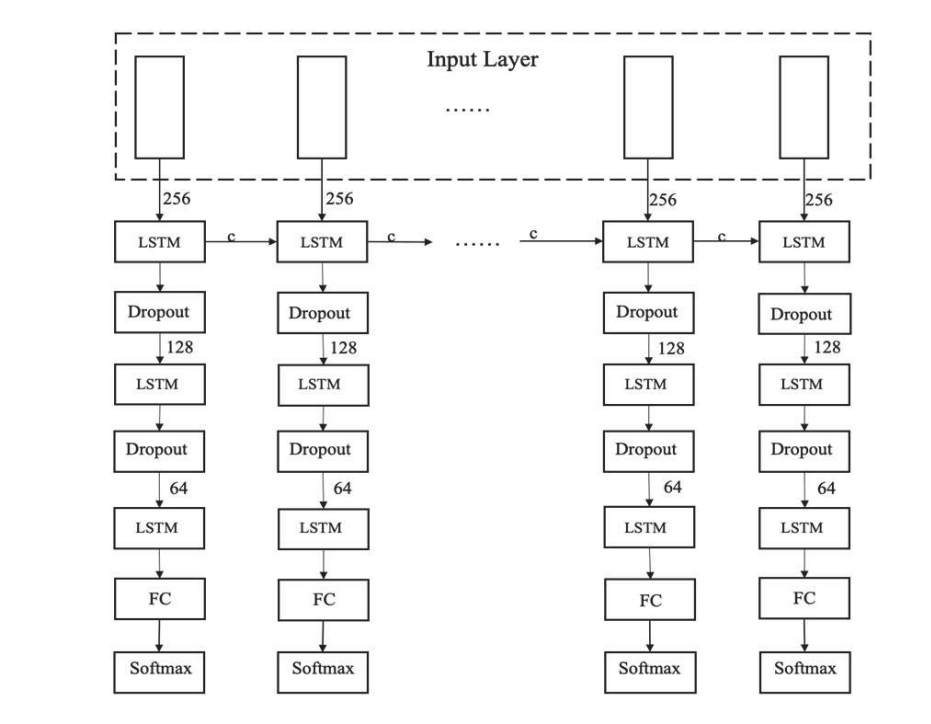
图2 神经网络架构图。
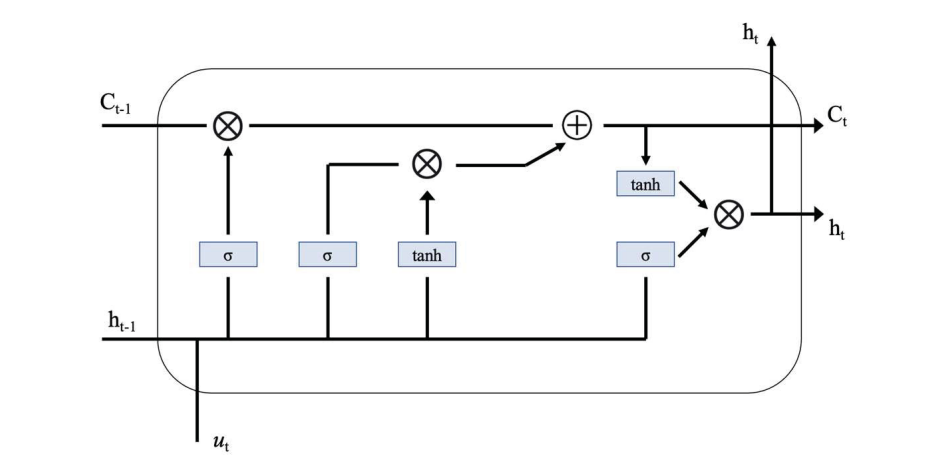
图 3 LSTM 单元。
3.4检测
在构建样本向量后,采用多层神经网络架构进行分类。最初,使用一维卷积神经网络处理输入向量。一维卷积层擅长捕捉样本向量内的局部依赖性和模式。在卷积层之后,架构集成了一个三层LSTM模块,以有效建模APT样本数据中固有的序列依赖性。完整的神经网络结构示意图,包括卷积层和三层LSTM模块,如图2所示。
第一个LSTM层有256个单元,处理由卷积层派生的初始特征表示。它捕捉数据中的初始时间关系。然后,第一个LSTM层的输出被输入到第二个LSTM层,该层由128个单元组成。这一层进一步细化了时间特征,并从较低级别的表示中抽象出更复杂的模式。最后,第三个LSTM层有64个单元,接收第二层的输出并继续时间特征提取过程。这种层次结构允许网络在不同尺度和抽象级别上捕捉时间依赖性。
然后,第三个LSTM层的输出被引导至一个全连接层,该层作为分类器。全连接层将LSTM学习到的高级特征转换为长度为2的向量,代表给定样本是APT或非APT的概率。这个输出用于实现APT检测器。
基于LSTM的APT检测器包含一系列基本LSTM单元,形成存储处理过的APT样本行为摘要的记忆存储层。图3显示了LSTM单元的架构。
在每个LSTM单元中,隐藏输出向量从LSTM单元传递到全连接(FC)层,并使用Softmax函数进行优化。以下递归方程(7)描述了这些LSTM单元的工作原理。
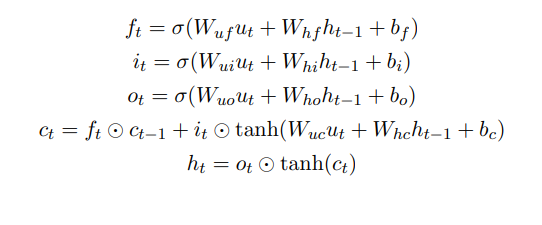
其中σ(x)是sigmoid函数,x ⊙ y是逐元素乘积,ut是输入向量,Wui∼hc是线性变换矩阵,bi、bf、bo、bc是偏置向量,it、ft、ot是门控向量,ct是单元记忆状态向量,ht是状态输出向量。
每个LSTM单元的信息记忆更新、遗忘和输出其状态由门控向量it、ft、ot决定。然后根据方程(7)改变单元状态ct和输出ht,并根据遗忘门控向量ft的状态决定是否重置或恢复单元状态。另外两个门控向量it和ot类似地调整输入和输出。
3.5同源性判定
源自同一APT(高级持续性威胁)组织的恶意样本往往具有部分相似的行为或功能,并且基因能够间接表达行为,所以属于同一团队的样本所共有的基因数量往往较多。本文采用K近邻(KNN)算法进行APT同源性判定。它基于特征空间中k个最相似样本的多数类别对样本进行分类。该算法仅依靠最近样本的类别进行分类。类似地,如果k个最近邻样本中的大多数属于某一类别,那么待分类样本就相应地被归到该类别。
KNN算法的性能取决于K值和距离定义。较小的K值对噪声敏感,而较大的K值可能会包含距离较远的样本,从而可能使预测产生偏差。样本分布不均匀会导致显著的误差。本文使用共享基因数量来衡量接近程度,如果样本共享的基因更多则认为它们更接近,这符合基因关联映射原理。
4. 评估
4.1环境与数据集
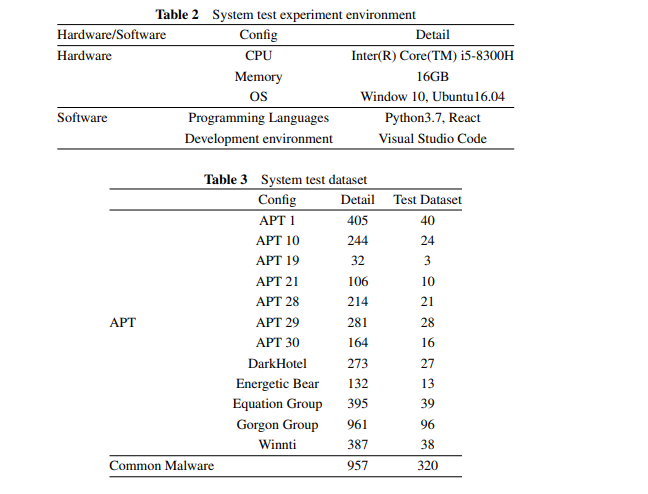
本文用于系统测试的实验环境如下表2所示。
实验中所使用的APT恶意样本数据集如下表3所示。特别需要指出的是,我们研究的核心数据集的突出特点在于其直接使用来自APT样本的原始可执行文件,从而高保真地反映了真实世界的场景。这些原始样本通过我们的系统进行处理,以创建一个检测与分类框架,该框架反映了在实际网络安全环境中所遇到的挑战,在实际环境中APT样本往往缺少标签且数量稀少。通过有意选择体现这些限制条件的数据集,我们的模型在网络安全系统所面临的条件下得到了严格的测试和验证,增强了其实际相关性和鲁棒性。
该数据集来自APT恶意软件数据集[23]。我们使用来自12个APT组织的3594个样本构建APT基因数据库并绘制APT基因关联图,并使用这些APT样本以及957个常见恶意样本对检测模型进行训练。使用来自12个APT组织的355个样本以及320个常见恶意样本对该系统进行测试。首先使用经过训练的APT检测模型进行预测并测试该模型的性能。最后,将被检测为APT的样本添加到基因图谱中,并展示基因图谱的变化。
4.2检测性能
基于上一节所实现的神经网络分类器检测模型,本节使用表3所示的数据集进行模型训练。训练集包含3876个样本,其中包括3239个APT样本和637个非APT样本,测试集包含675个样本,其中包括355个APT样本和320个非样本。测试指标包括准确率(Accuracy)、精确率(Precision)和召回率(Recall),它们通过公式(8)计算:

其中,TP是检测模块预测为正类的正样本数量;TN是检测模块预测为负类的负样本数量;FP是检测模块预测为正类的负样本数量;FN是检测模块预测为负类的正样本数量。
首先,本文构建了一个基于全连接神经网络的分类器用于实验。训练环境和所使用的深度学习框架如表4所示。
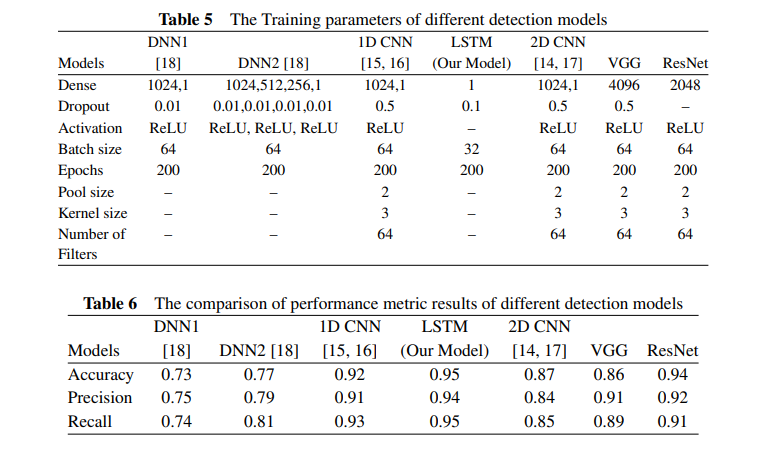
所提出的检测模型(LSTM模型)以及其他对比神经网络检测模型的训练参数如表5所示,均使用Adam优化器并将初始学习率设置为10^{-4},损失函数采用交叉熵损失(Cross Entropy Loss)。这些检测模型之间的输入训练数据略有不同,其中DNN1、DNN2、2D – CNN、VGG和ResNet所处理的输入训练数据是由输入恶意软件样本生成的灰度图像特征,而1D – CNN和LSTM使用样本的API特征。
不同检测模型在性能指标(如准确率、精确率和召回率)上的对比结果列于表6。所提出的LSTM网络检测模型在准确率、精确率和召回率上均取得了最佳得分。LSTM网络的模型架构规模也比其他神经网络检测模型更为简洁。
不同检测模型之间的模型训练准确率和损失的对比结果如图4所示。随着模型训练轮次(epochs)的增加,在25到200轮次范围内,所提出的LSTM检测模型的平均准确率高于其他检测模型,平均损失低于其他检测模型。结果表明,所提出的基于LSTM的检测模型在APT样本识别和来源分类方面具有最佳的评估性能,通过该模型我们可以轻松识别出来自已知APT组织的样本或常见的恶意软件。
4.3同源性判定评估
基于上一节所实现的同源性判定模型,系统使用表3中的335个APT样本对由3239个APT样本形成的基因池进行了同源性判定测试。KNN算法的核心参数是K值。系统测试了K值对同源性判定准确性的影响,其与准确性的关系如图5所示。
假阳性率(FPR)和假阴性率(FNR)是根据分类结果生成的混淆矩阵计算得出的。如附录图6所示,混淆矩阵阐明了每个APT类别中真阳性、假阳性、假阴性和真阴性的分布情况。假阳性率是通过将假阳性出现的次数除以假阳性和真阴性的总和来确定的,从而深入了解非同源样本被错误分类为同源样本的频率。相反,假阴性率是通过将假阴性的数量除以假阴性和真阳性的总和得到的,可了解系统将同源样本误分类为非同源样本的倾向。
经检查发现,APT – 19的假阳性率明显较高。这可归因于KNN算法的固有局限性,即分类决策基于最近邻的多数投票。APT – 19在数据集中的样本数量较少,更容易被样本量较大的其他类别所掩盖。因此,APT – 19的假阳性率反映了系统在对样本数量稀少的类别进行稳健分类时所面临的挑战。
这种全面的评估框架,包括假阳性率、假阴性率指标以及准确性,能够更细致地了解系统的能力和局限性,从而有助于在实际场景中部署该系统时做出明智的操作决策。
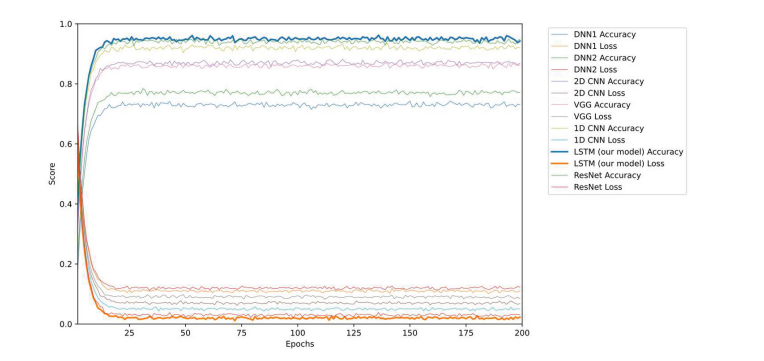
图4 不同检测模型的准确率与损失比较。
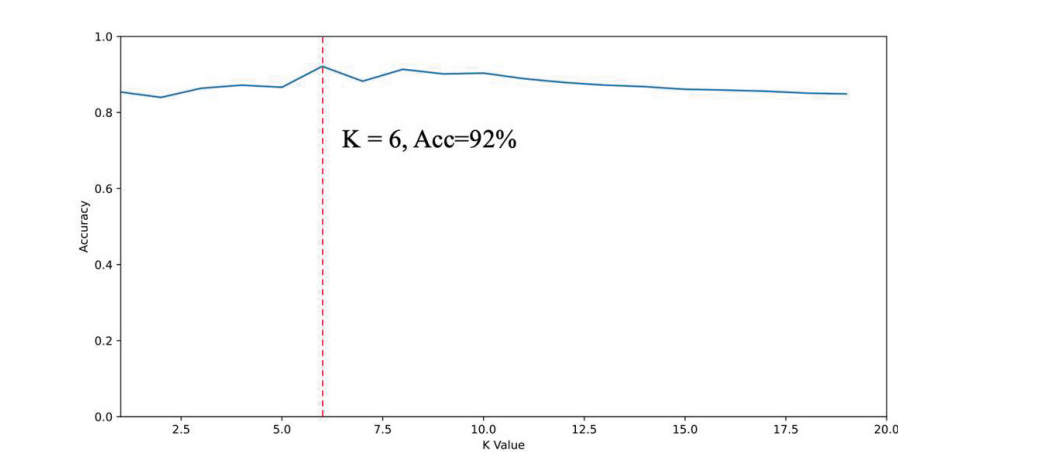
图5 K值对分类结果的影响。
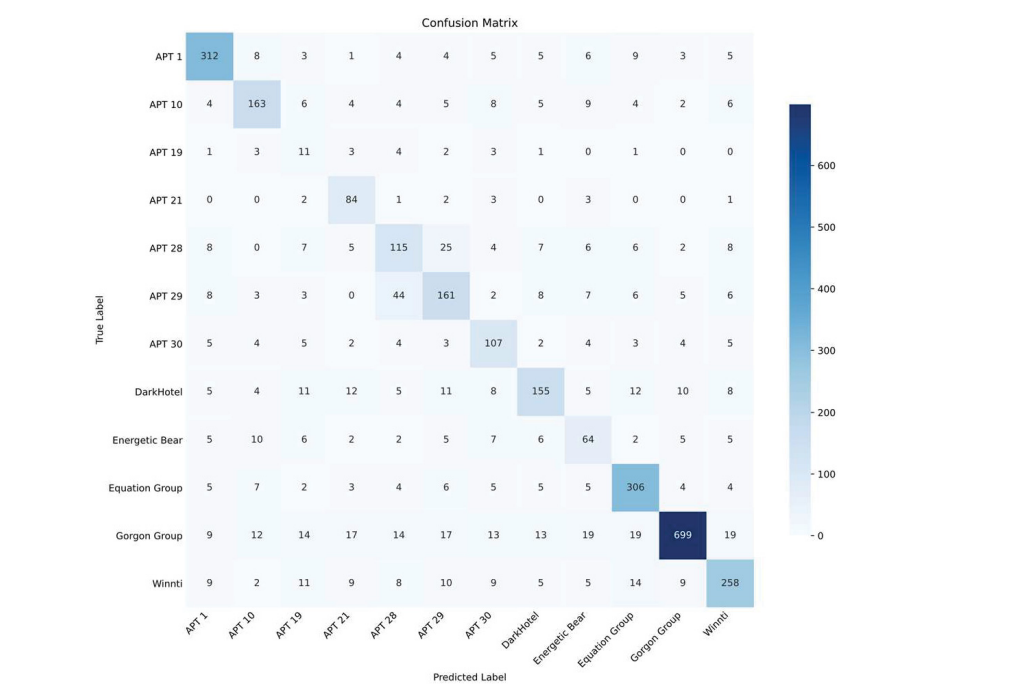
图 6 混淆矩阵。
4.4 APT基因关联图
根据上一节所描述的方法,本文绘制了每个APT组织内的基因关联图。图7展示了APT – 1组织内的关联图,该图可直观地表明源自同一APT组织的恶意代码之间存在明显的基因共享,反映出这些样本之间相互借鉴较多,并且包含许多相似的行为和功能。
基于APT组织内的基因关联图绘制,我们绘制了APT组织之间的基因关联图。对于任意两个不同的APT组织,如果存在的共享基因数量大于设定阈值,就在这两个APT组织之间用一条线标记,线的粗细反映具有共享基因的样本数量。完整的基因关联图如图8所示。可以看出,大多数组织之间都存在相互关联,但关联程度较弱。
APT – 28、APT – 29和Energetic Bear组织之间存在较强的基因关联,其中APT – 28和APT – 29的基因共享程度最强,在本文的评估指标中达到了4.2。了解APT组织之间的相关性对用户有以下几方面的益处:
(1) 强化防御策略:通过了解APT攻击者的行为倾向和战术、技术与操作程序(TTPs),用户可以加强自身防御。例如,如果某些APT组织偏好特定的恶意软件或攻击方法,用户可以主动实施应对措施。
(2) 快速响应:了解APT组织之间的关系有助于用户迅速识别并应对联合攻击。如果两个组织之前有过协作,其中一个组织出现异常活动可能预示着即将发生攻击,从而促使更快速的响应。
(3) 战略决策制定:对APT组织相互关联的深入了解有助于用户做出明智的战略决策。例如,如果用户频繁成为某些APT组织的攻击目标,他们可能会分配更多资源来抵御这些威胁。
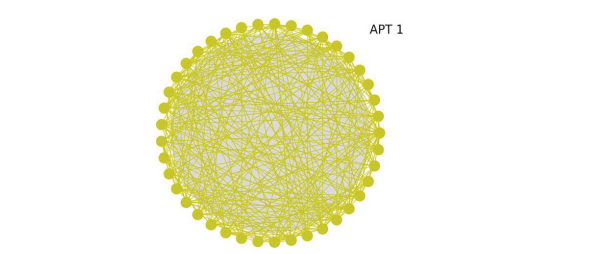
图7 APT-1基因关联图。
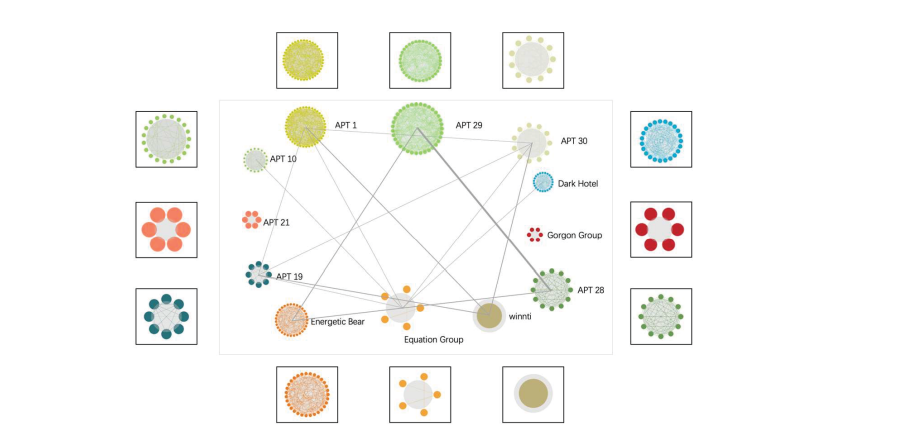
图8 APT组间的基因关联图。
5. 结论
APT(高级持续性威胁)攻击对企业和国家的网络安全构成了重大威胁。本文针对传统特征码匹配技术难以识别新的恶意软件这一局限性,提出了一种通过基因图谱进行恶意软件识别的方案,该方案从生物遗传学中获取灵感,将恶意软件进行关联并开展同源性分析。
本文设计了一个针对APT样本的同源性判定系统。首先,该系统通过合并软件代码的基本块来提取APT样本基因,运用TF – IDF算法筛选特征基因,并利用Word2Vec算法构建基因特征。基于三层LSTM(长短期记忆)的分类器用于检测APT样本,而KNN算法用于判定APT样本的同源性。基因图谱有助于快速、准确地识别APT攻击特征,提高检测效率。
实验结果表明,在检测过程中APT基因图谱不断丰富,能够全面呈现APT关联并具备样本检测能力。用户可以通过上传样本来与基因图谱交互,从而了解APT组织的关联并检测APT攻击。该系统解决了在恶意软件中准确识别APT攻击代码存在及可追溯性的难题。
