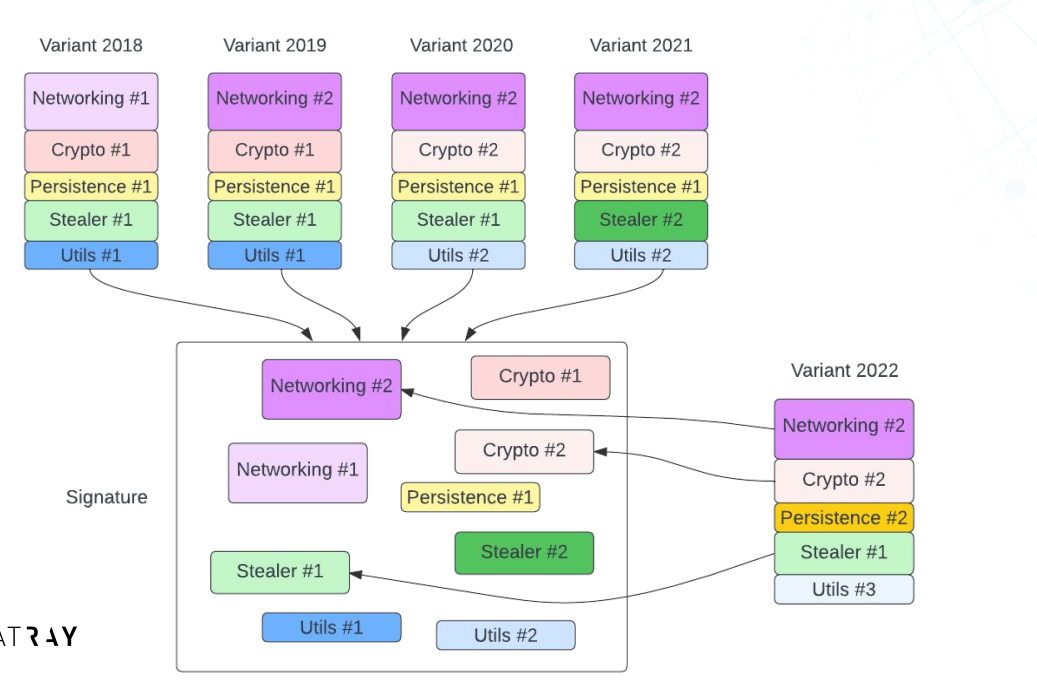
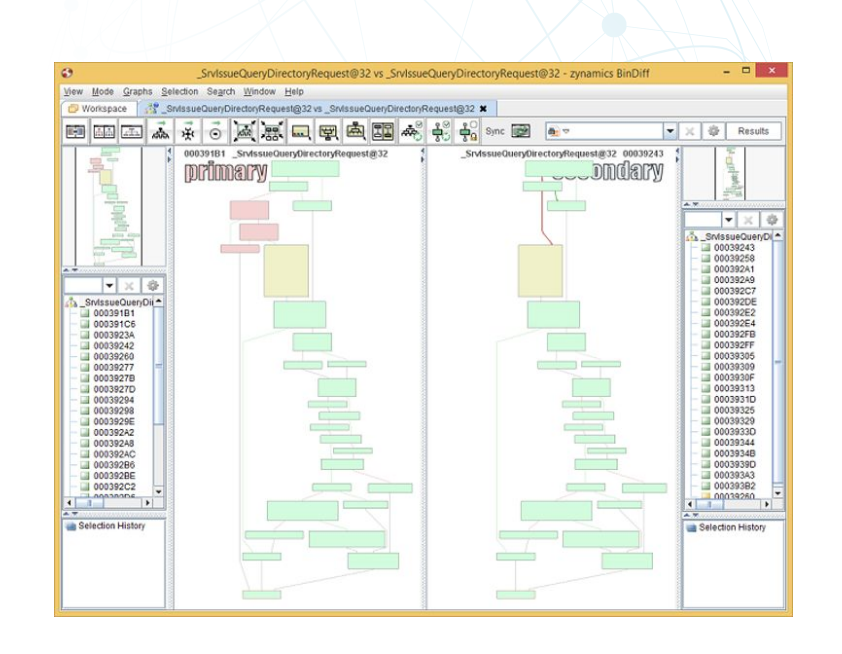
概述
Botconf 是一个致力于了解恶意软件生态系统和僵尸网络的会议。 它是由一群朋友于 2012 年构思出来的,他们认为有必要召开一次会议,从各个角度关注这个主题,包括恶意软件本身、它背后的人,以及防范它的方法。 Botconf 背后的团队由女性和男性组成,他们的日常生活致力于保护他们的组织、了解网络威胁和培训他人 1。
该会议通常会聚集来自世界各地的 400 名来自不同背景的人,包括执法部门、学术界、CSIRT、威胁分析团队、防病毒开发人员等。 他们都有一个共同的目标,那就是打击恶意软件。 会议的第一天专门用于小型研讨会,主要会议将在接下来的三天内举行。 有很多机会交流思想和知识,享受美食 2。
BotConf 2023
https://www.botconf.eu/past-editions/botconf-2023/
使用系统的代码重用分析创建健壮的 YARA 规则
YARA 是检测和识别恶意软件的常用工具。大致有两种用于二进制文件的 YARA 规则:1) 基于元数据和字符串,2) 基于代码。
基于代码的 YARA 规则有一定的好处。由于代码重用在恶意软件家族的二进制文件中很常见,因此它提供了大量选项来作为 YARA 规则的基础。如果所选代码在二进制文件中被大量重用,那么它可以产生非常健壮的规则。
这种方法带来了某些挑战。一个关键方面是能够在恶意软件家族的许多二进制文件中找到大量重复使用的代码。除非有某种自动化在起作用,否则这很快就会变得困难且耗时。一旦确定了合适的重用代码,就需要将其转化为 YARA 规则,这样即使涉及编译器差异、优化或指令集更改,它也能正常工作。
在本次研讨会中,我们将基于自动识别一个家族的许多二进制文件之间的共享代码,为少数恶意软件家族创建强大的 YARA 规则。
目前两种用于二进制文件的 YARA 规则,基于文本字符串或基于字节。目前大多数公开可用的规则主要有(文本)字符串组成。
根据代码创建yara规则
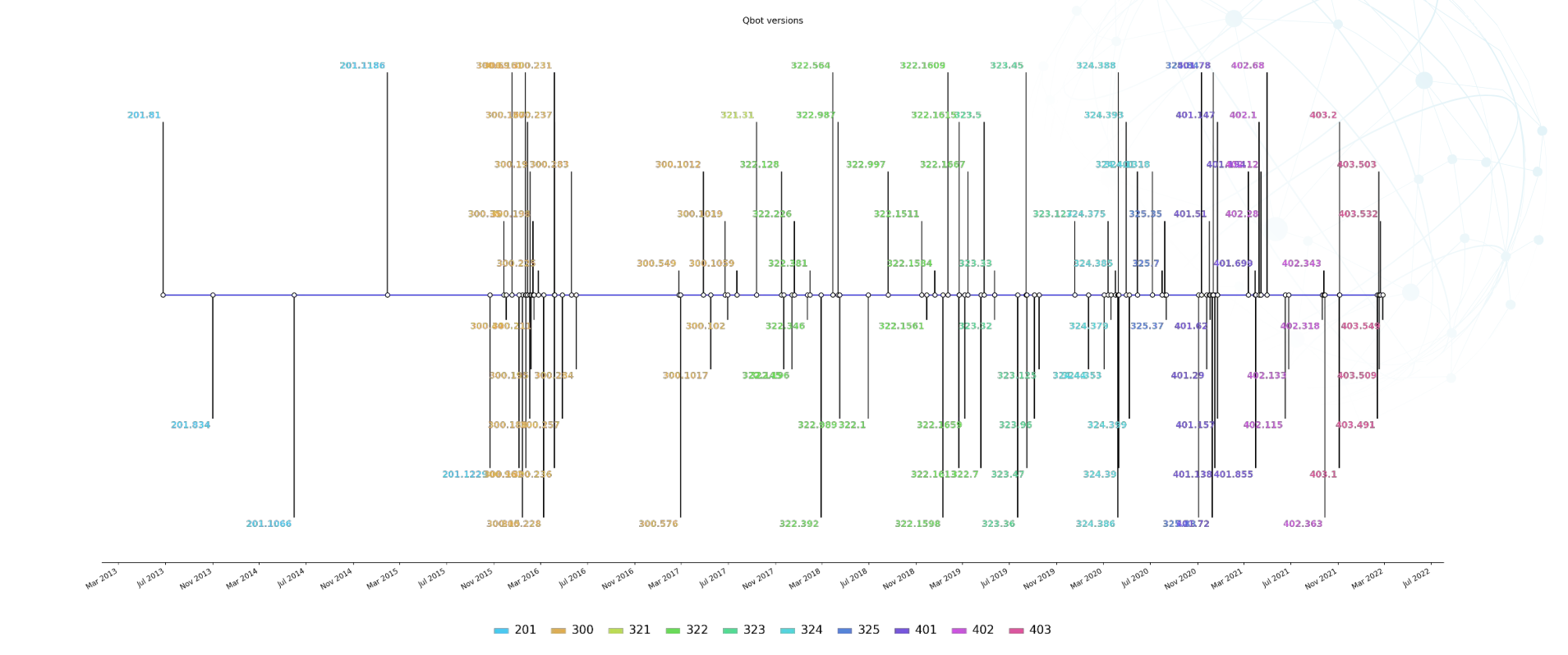
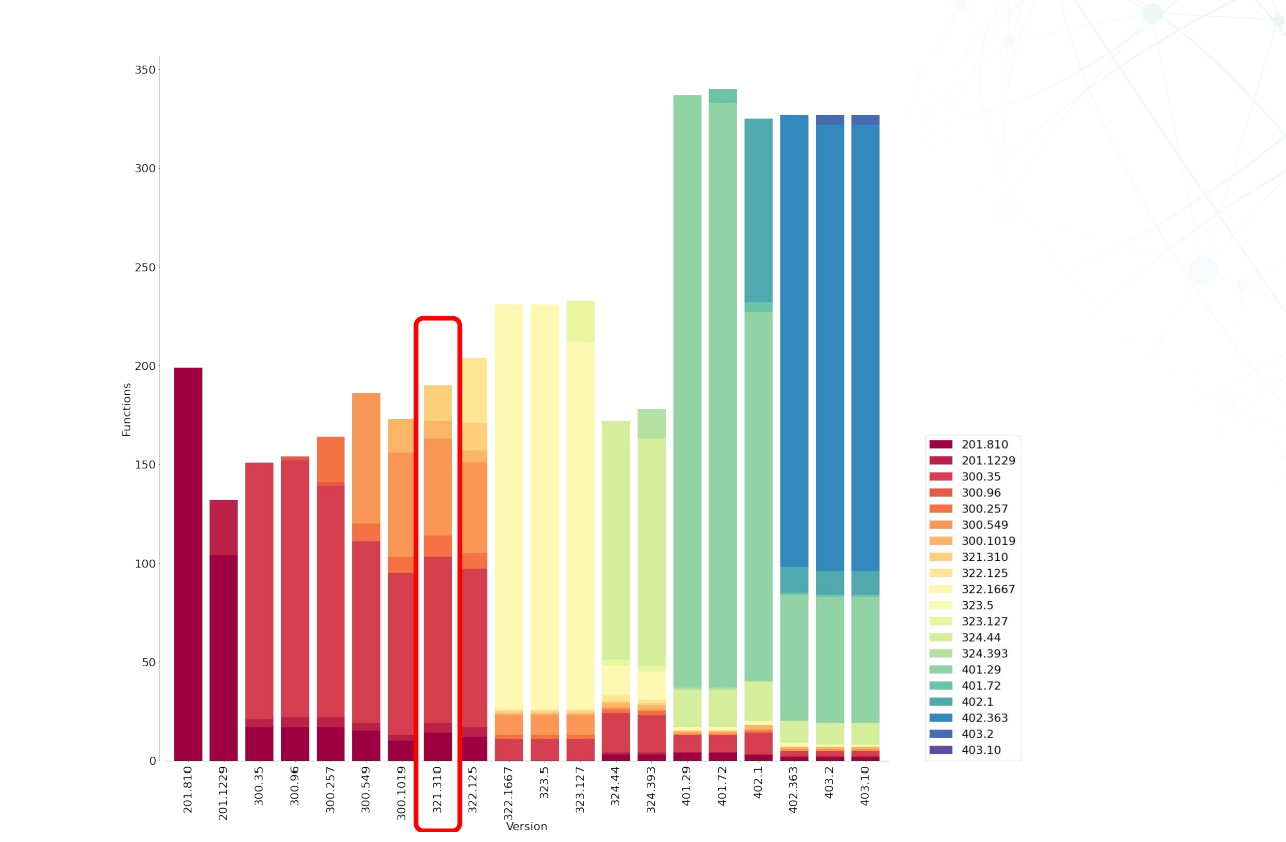
Qbot代码寿命:
什么是好的基于代码的规则?
唯一代码:所选代码对一个家族是唯一的,可识别的
规范化代码:独立于位置/重定位/操作数
规范条件:对恶意软件代码的更改具有一定的广泛性/弹性 ,不要太死板
寻找唯一代码
1. 确定大量二进制文件之间的相关代码重用
- 排除好的软件代码
- 排除恶意软件家族”分支“
2. 我们将处理这个代码搜索引擎,它允许我们:
- 首先创建”基于代码“签名,然后允许将其转化为yara规则
- 签名的预验证
- 缩放到>数千个二进制
规范化代码

使用mkYARA规范化代码

规范条件
1. 我们希望对代码的更改具有一定的广泛性和弹性
- 这意味着我们需要想规则中添加的不仅仅是几个函数后基本块
- 并且有有一个灵活的规范条件,比如20%的阈值 -> 自动化
2. 根据我们在1000多个恶意软件家族中大规模研究代码重用的经验:即使是很小的重叠10-20%的含量足以保证高质量的鉴别
代码搜索引擎-寻找大规模代码重用
代码搜索引擎是什么?
寻找大规模代码重用是什么?
基于代码签名是什么?
需求
粒度:需要有一个精细的代码重用粒度,无论是函数级还是子函数级
准确性:需要一个高质量的代码相似度度量来确定代码重用
规模:需要同时查看数十到数百个恶意软件家族的二进制文件
| 粒度 | 精度 | 规模 | |
| ssdeep | × | × | × |
| Bindiff | √ | √ | × |
| code search engine | √ | √ | √ |
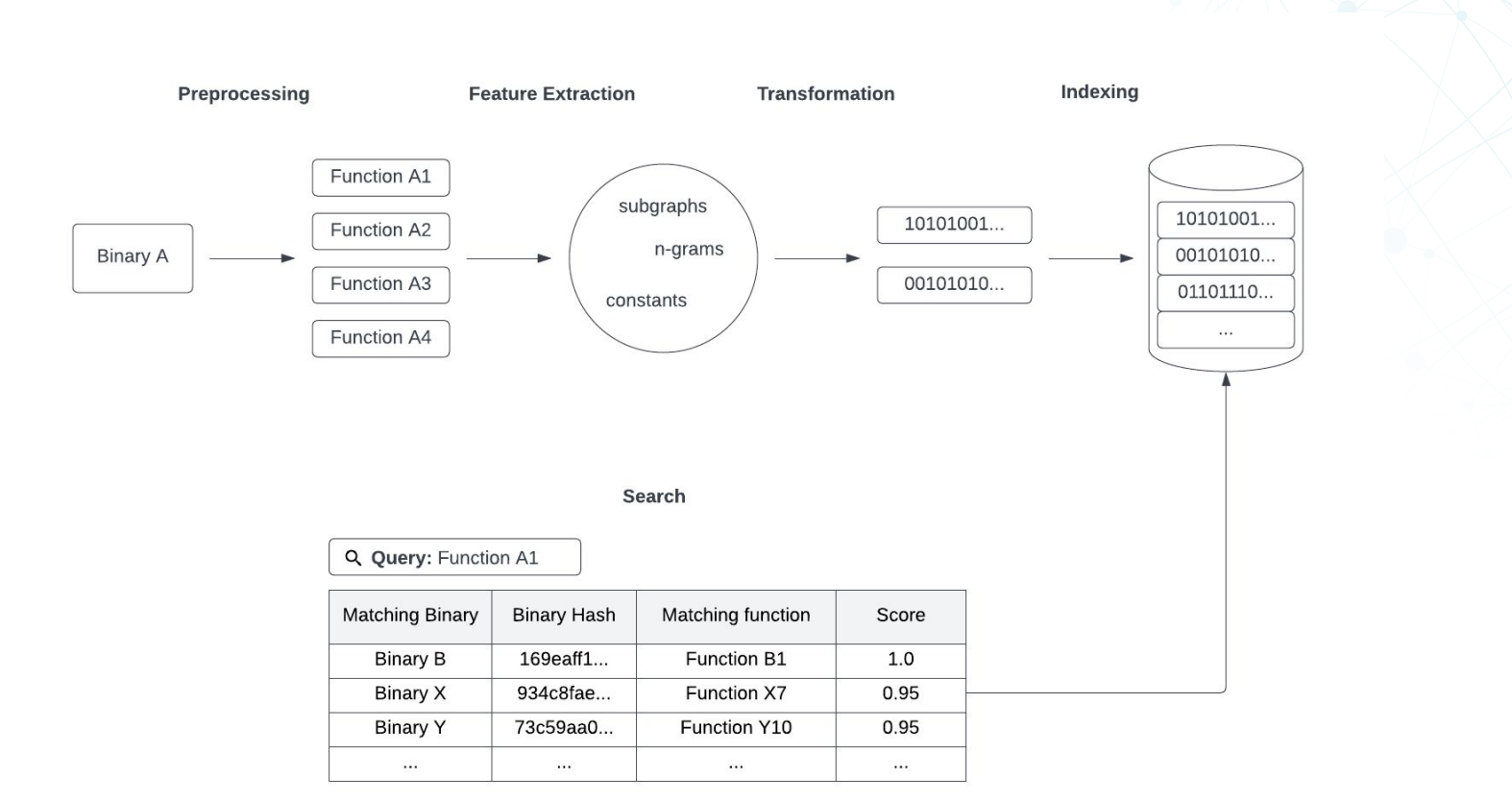
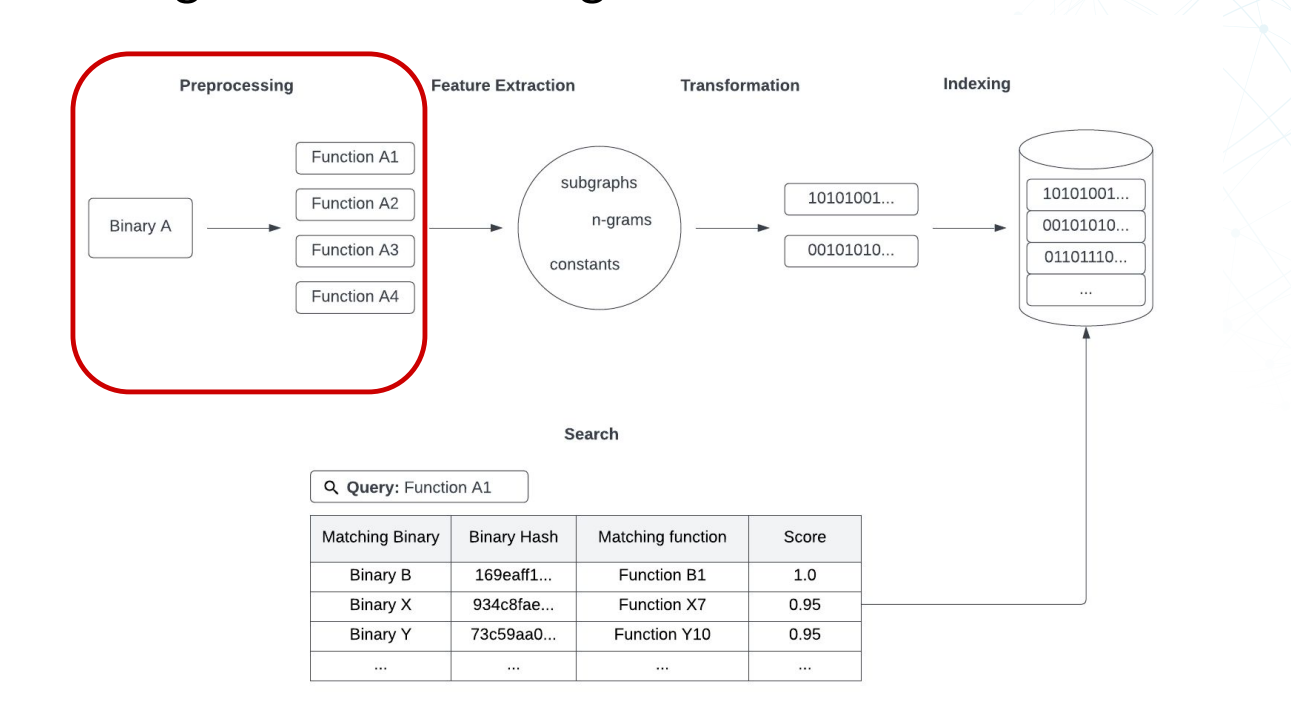
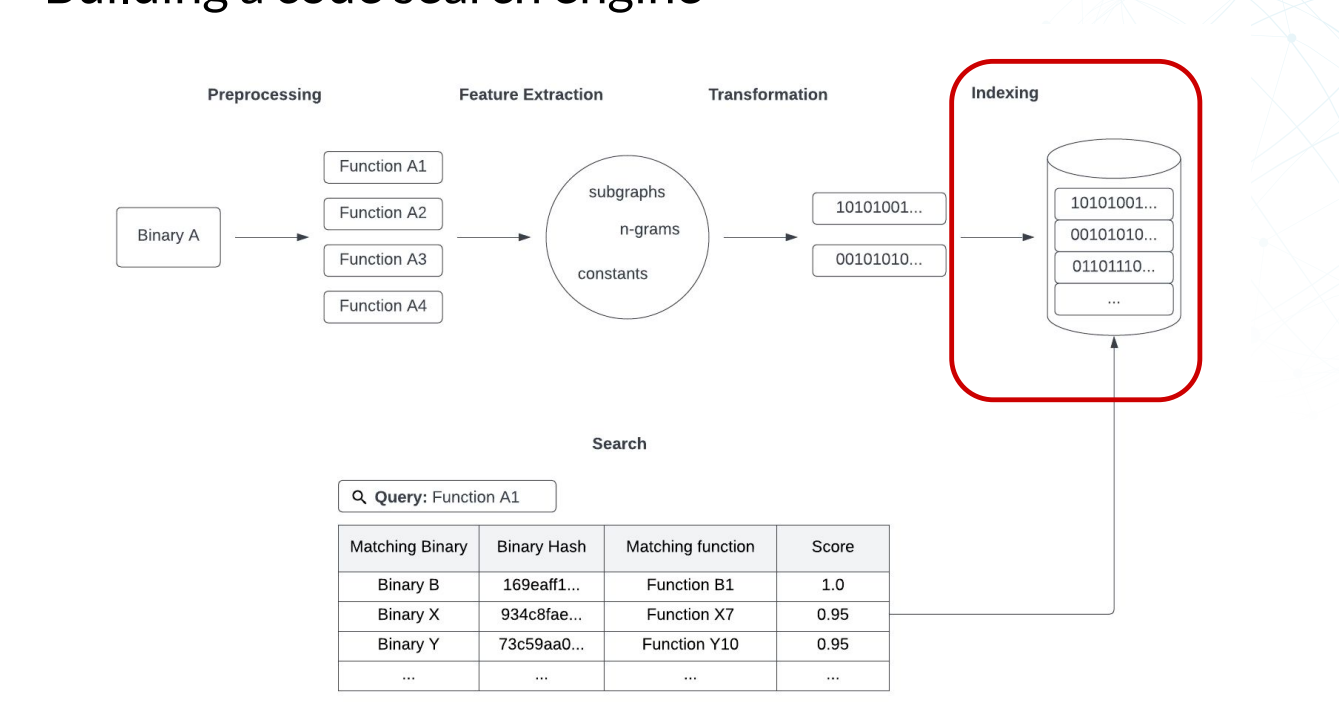
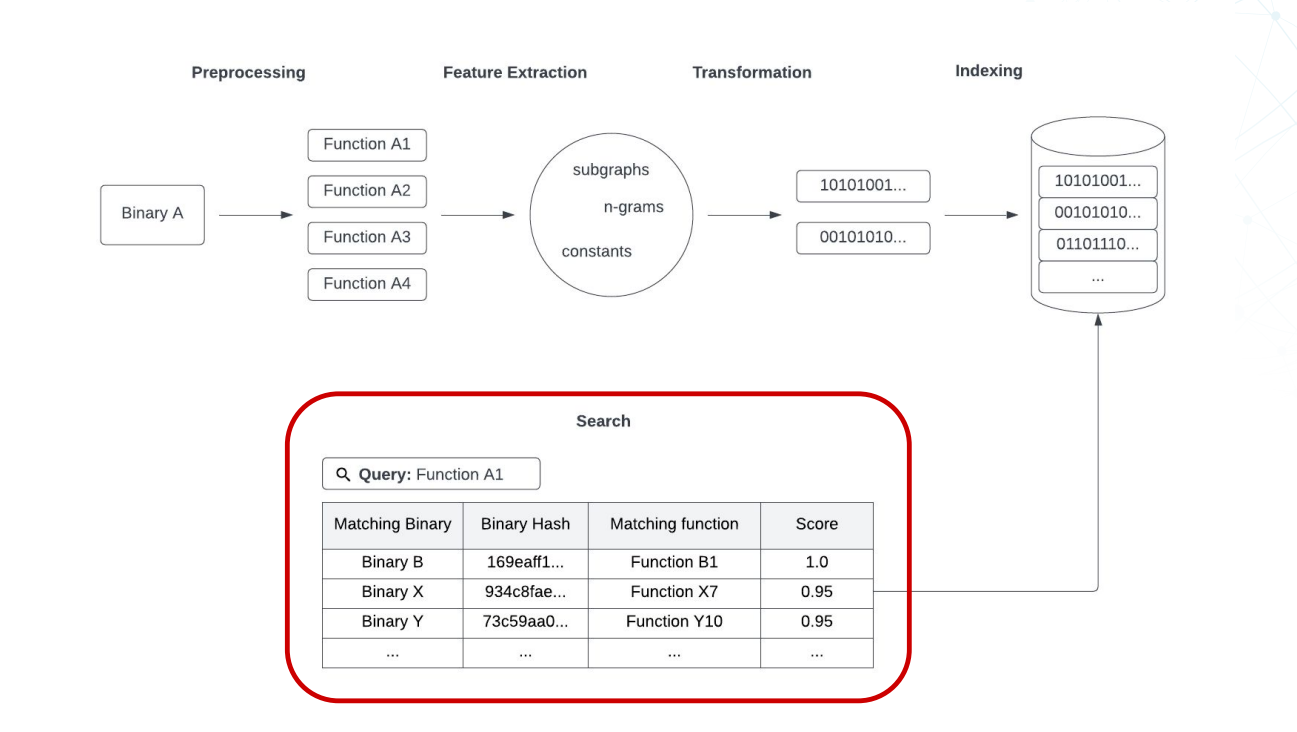
代码搜索引擎的架构
二进制文件 – 预处理 – 多个函数 – 特征提取 – subgraph/n-grams/constans – 转换- 二进制数据 – 索引 – 二进制索引 – 搜索 – 搜索数据
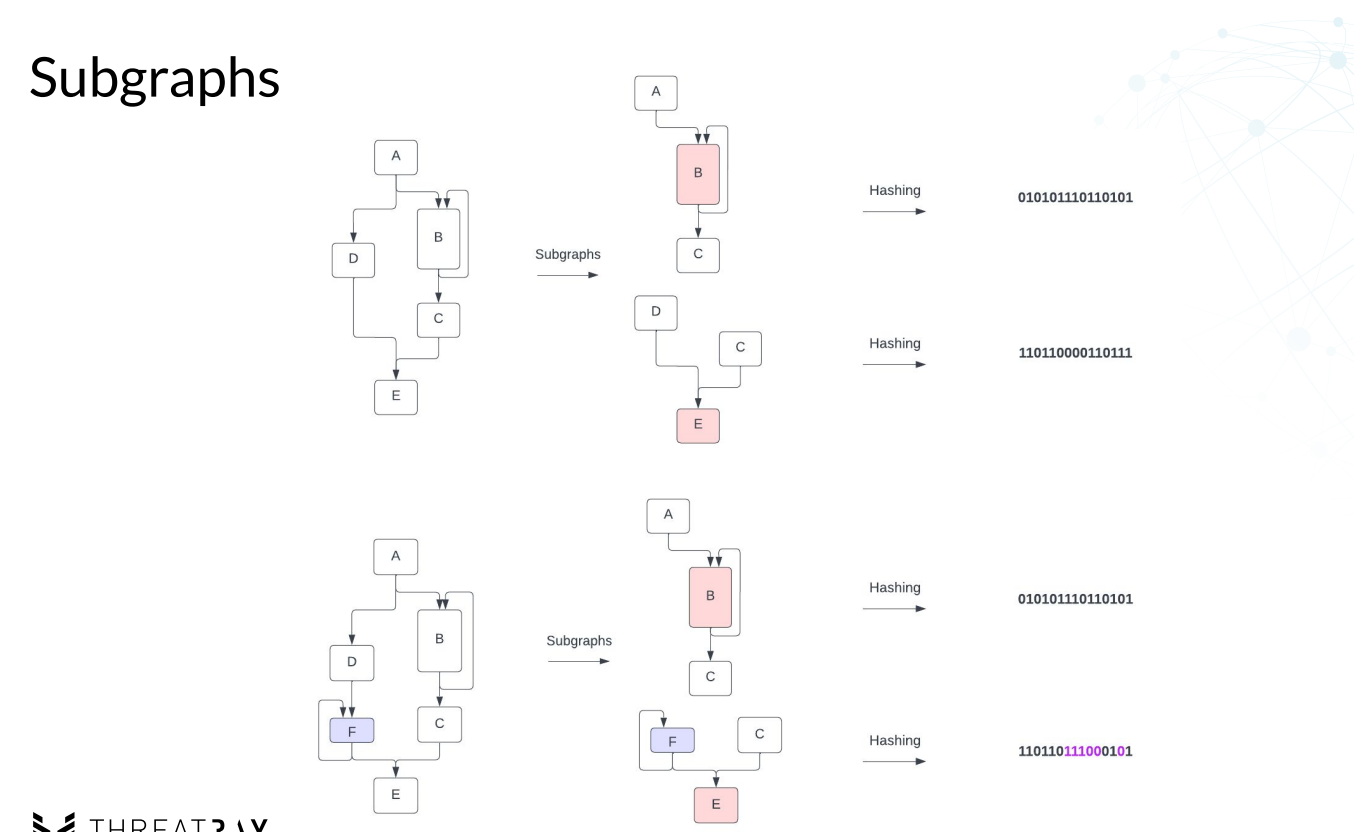
- 子图(subgraph)是指通过将函数的控制流图转换为子图,将函数的执行路径表示为节点和边的集合。这样可以捕获函数内部的控制流行为,例如条件分支、循环和函数调用。
- n-grams 是将函数的指令序列划分为连续的 n 个指令片段,并将这些片段作为特征进行提取。n-grams 可以捕获函数的局部指令模式和常见操作序列。
- 常数(constants)特征提取是指从函数中提取出使用的常数值。常数可以是整数、浮点数、字符串等,在二进制代码中常常包含有意义的信息,例如密钥、硬编码的地址或字符串。
⬇ ⬇ ⬇ ⬇ ⬇
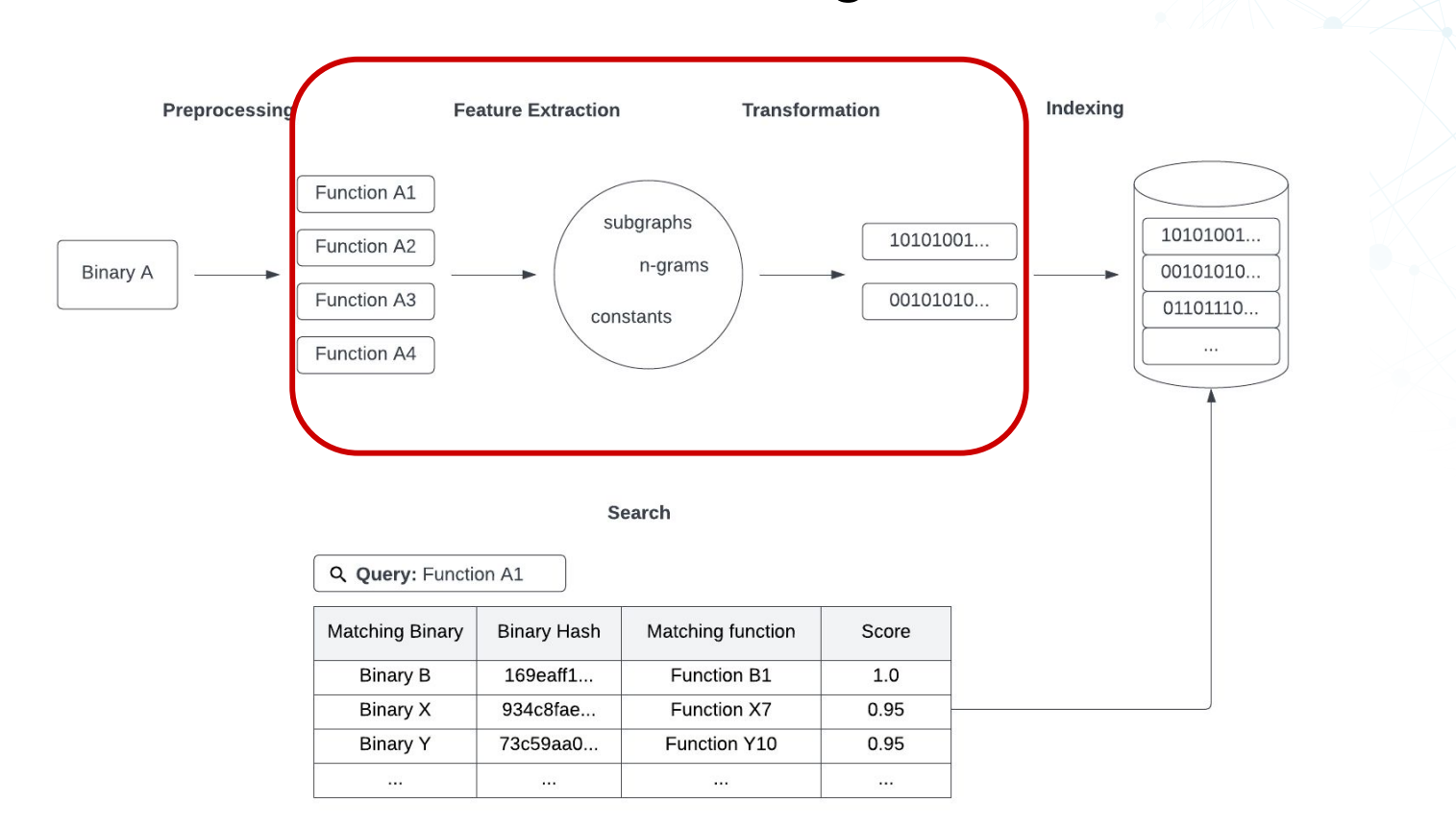
代码搜索引擎的核心部分
搜索粒度、代码相似度度量、保持距离转换
搜索粒度
1. 二进制:适合回溯狩猎,二进制OSINT
2. 函数:
- 具有语义值得独立代码片段
- 重用很大程度上是由开发人员触发的
3. 基本块:
- 具有语义值得最小代码单元
- 重用很大程度上是由编译器触发的
什么是好的代码相似度度量?
1. 语义与语法代码相似度
2. 对代码生成差异的弹性
- 位置依赖编
- 译器版本
- 编译器优化级别
- 字尺寸(32或64bit)
- CPU架构
3. 对源代码中微小差异的弹性(近似语义相似)
指令序列相似度
1. 基本块 -> 规范化代码
- BinLex称其为”Traits“
2. 优点
- 简约易懂的方法
- 细粒度相似性度量
3. 缺点
- 在代码生成中,即使很小的变化也很弱
- 每个函数需要大量的数据,这使得它很难扩展

控制流图相似度
1. 涉及到一个图同构我呢提,这是一个很难求解的问题
2. 相似度是从图A到图B的基本块匹配
3. 优点
- 对代码生成更改具有良好的弹性
- 可扩展到100M+功能
4. 缺点
- 质量很大程度上取决于特征提取过程
保持距离转换
1. 我们需要能够在规模上有效地比较代码
- 指令序列相似性 – > 存储爆炸
- 控制流图相似度 -> cpu密集型
2. 解决方法是进行距离保持变换
3. 目标是计算后表示相似度,其性质为
- 相似度很容易计算
- 表示上的相似=实际代码中的相似
4. 这通常是位置敏感的散列(模糊散列)或嵌入到低维向量空间
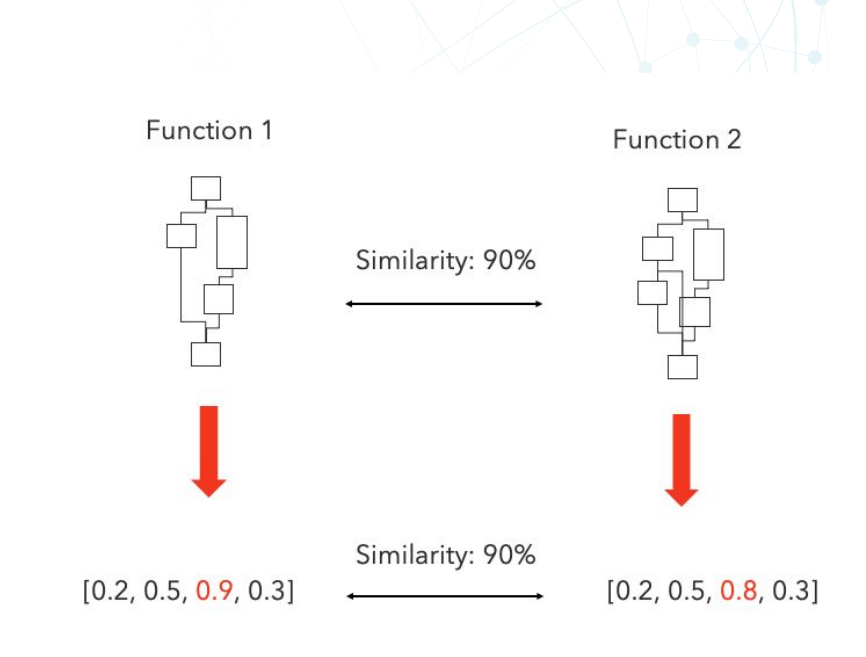
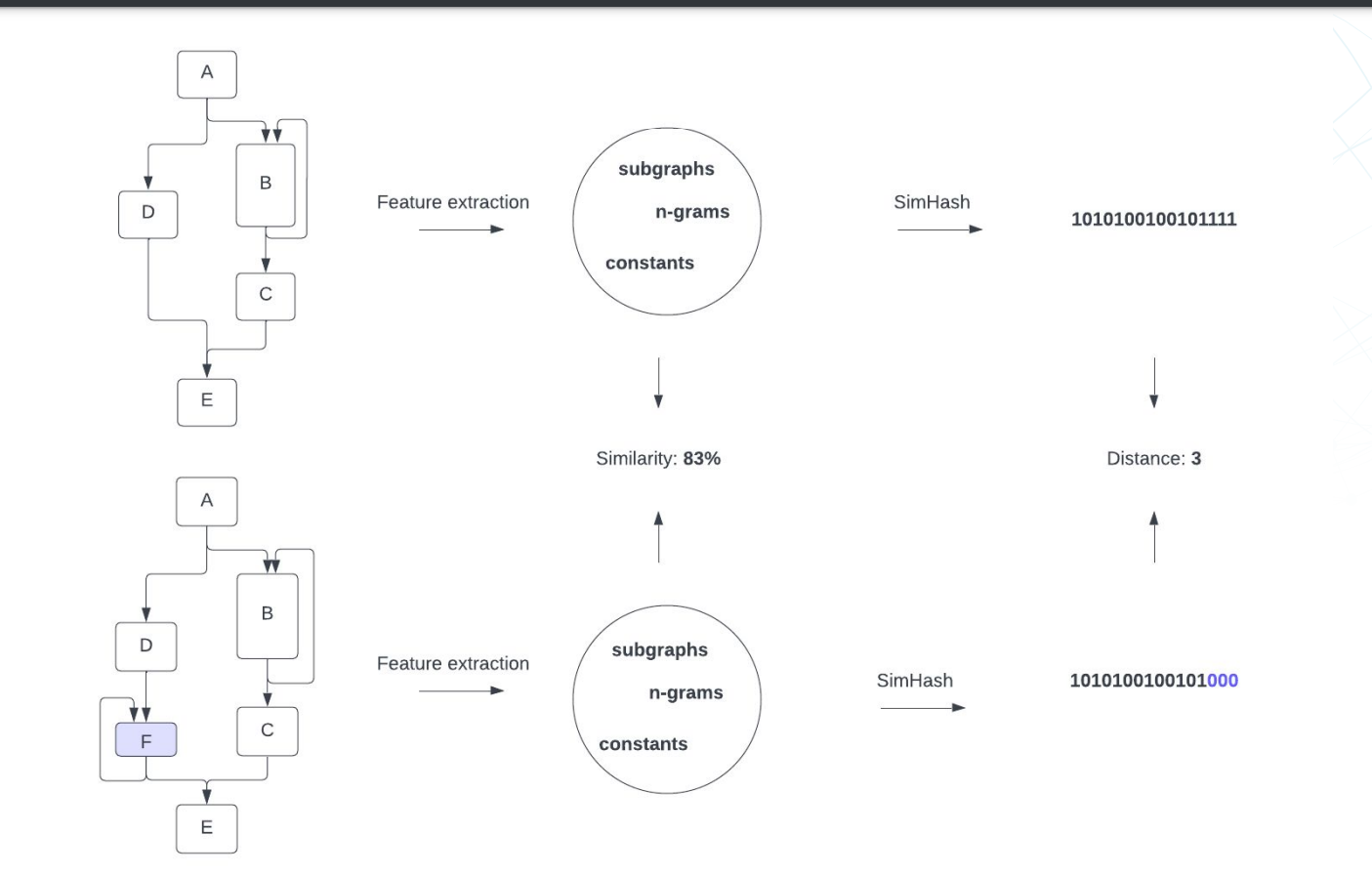
函数的SimHash
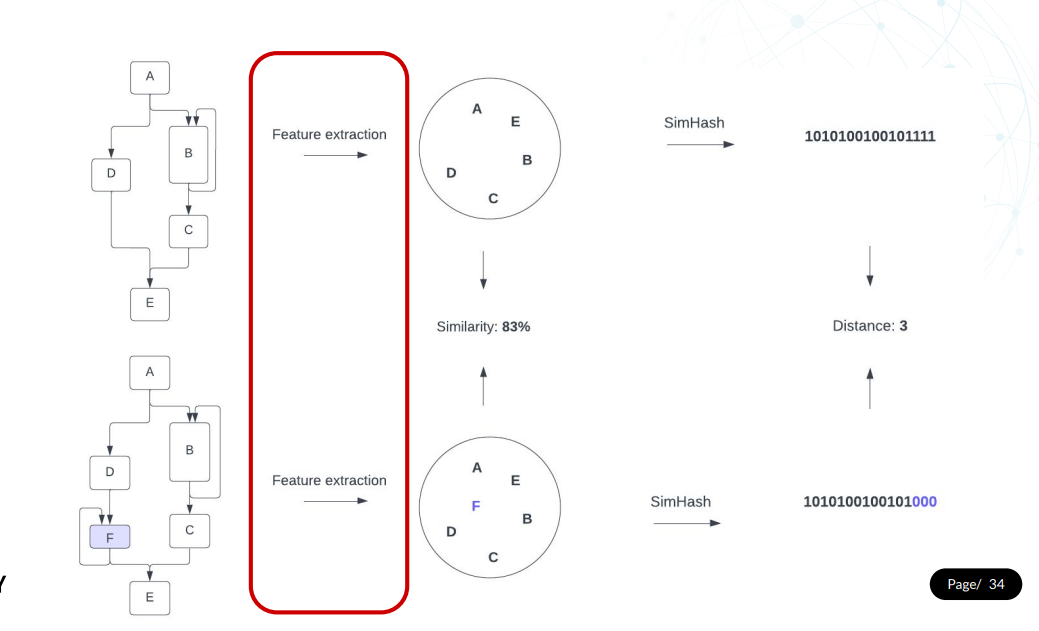
从控制流图特性到SimHash
1. 我们需要提取符合前面概述的需求的特性,例如,对代码生成中的变化具有弹性
2. Functon SimSearch使用三种类型的特性来实现这一点:
- 控制流图的子图
- 指令序列助记符中的N-grams
- 函数中的常数
子图
助记符的n-grams

指令序列中的常量
1. 某些常量通常不会被编译器改变,因此它们是代码重用的相关标识符
2. FunctionSimSearch只考虑以下常量
- 大于0x4000
- 能被4整除且大于10的
3. 通过移除堆栈偏移的想法,这不是一个好的特性
SimHash For Functions
构建代码搜索引擎
例1:BinLex
1. 预处理:用capstone拆卸
2. 特征提取:提取规范化指令序列(“traits”)
3. 转换:对特征应用加密散列
4. 索引:将特征哈希映射到特征的查出,没有相似性度量
5. 搜索:对输入特征id(哈希)进行索引查找,返回元数据
例2:FunctionSimSearch
1. 预处理:用dyninst拆卸
2. 特征提取:从函数的控制流途中提取子图、n-grams和常量
3. 转换:对特征提取应用SimHash
4. 索引:将SimHash划分为多个倒排序索引桶
5. 搜索:通过索引匹配输入函数(SimHash)并返回函数与元数据
构建yara规则创建管道
Yara规则创建管道
BinLex:
1. 建立二进制索引
- 解析二进制
- 提取特征(归一化)
- 过滤特征(如按指令数量)
- 索引过滤特征
2. 创建代码签名
- 将样本共享特征添加到代码签名中
- 从代码签名中删除白名单特征
- 从其他代码签名中删除共享特征
- 测试代码签名
3. Yara规则创建
- 生成带有代码签名特征的yar规则
- 测试yara规则(不断调整条件)
FunctionSimSearch:
1. 建立二进制索引
- 解析二进制
- 提取特征(归一化)
- 使用SimHash的索引函数
2. 创建代码签名
- 根据相似度选择候选函数
- 测试通配符函数
3. Yara规则创建
- 生成带有代码签名特征的yar规则
- 测试yara规则(不断调整条件)
4. 如果共享函数不是100%相似,BinLex将用于创建带有特征的通配符函数

