自然语言处理自动标记网络威胁情报报告
Hamza Abdi,Steven R. Bagley,Steven Furnell和Jamie Twycross
诺丁汉大学计算机科学学院
英国诺丁汉,NG8 1BB
{hamza.abdi,steven.furnell,jamie.twycross}@nottingham.ac.uk;srb@cs.nott.ac.uk
摘要
在应对高级持续威胁(APT)攻击时,归因为我们提供了宝贵的情报。通过准确识别攻击背后的罪魁祸首和行为者,我们可以更深入地了解他们的动机、能力和潜在的未来目标。网络威胁情报(CTI)报告被用于有效归因这些攻击。这些报告是由安全专家编制的,提供了有关威胁行为者及其攻击的宝贵信息。
我们有兴趣构建一个完全自动化的APT归因框架。其中一个关键步骤是从CTI报告中自动处理和提取信息。然而,CTI报告大部分是非结构化的,这使得信息的提取和分析变得困难。
为了开始这项工作,我们引入了一种方法,可以自动突出显示CTI报告中所归因的主要威胁行为者。这是通过使用基于spaCy库的自定义自然语言处理(NLP)模型来完成的。此外,该研究展示了并突出了在这项工作中使用的各种pdf转文本Python库的性能和有效性。此外,为了评估我们模型的有效性,我们对一个包含605个英文文档的数据集进行了实验,这些文档是从互联网的各个来源随机收集的,并进行了手工标记。我们的方法达到了97%的准确度。最后,我们讨论了自动处理这些文档所面临的挑战,并提出了一些解决方法。
ACM参考格式:
Hamza Abdi, Steven Bagley, Steven Furnell, and Jamie Twycross 2023.
使用自然语言处理自动标记网络威胁情报报告。在2023年ACM文件工程研讨会(DocEng ’23)论文集中。ACM,爱尔兰利默里克,4页。
https://doi.org/10.1145/3573128.3609348
CCS概念
• 信息系统 → 信息检索
• 安全与隐私 → 入侵/异常检测与恶意软件缓解
• 计算方法 → 人工智能 → 自然语言处理 → 信息提取
关键词
高级持续威胁,网络威胁情报报告,归因,自然语言处理,spaCy。
1 引言
网络攻击的归因是识别和分析网络攻击或事件背后的来源、行为者和动机的过程。准确归因高级持续威胁(APT)攻击对于制定有针对性的对策、加强数字防御、追究责任方的责任以及预防未来攻击至关重要[1]。在一个日益互联的世界中,理解和应对APT组织带来的威胁变得更加重要,因为它们的攻击被认为是高度复杂的,可能造成巨大的损害[2]。归因网络攻击使用了几种方法,每种方法都有其优点和缺点。例如:
– 网络事件/工件分析。[3]
– 对恶意软件进行解剖和逆向工程,以识别独特特征。[4]
– 分析攻击者的行为。[5]
其中一些方法依赖于详尽的报告,包含有助于归因过程的有用信息。这些报告可能包含网络工件,经过分析后可以提供有关攻击和攻击者的见解。此外,它们提供了关于攻击的性质的更多背景信息:攻击者的方法、策略、技术和程序(TTPs),以及APT威胁格局的更清晰图景[6]。这些报告被称为网络威胁情报(CTI)报告。它们由网络安全专家生成,这些专家从各种来源(如网络流量、恶意软件样本和开源情报)收集、分析和解释数据。它们是网络安全社区内有效合作的基础[7]。
然而,这些报告的主要问题在于它们实际上是非结构化文档,因为它们缺乏标准化,这使得从报告中自动提取信息成为一个复杂的过程。当前的研究旨在开发一种自动的高级持续威胁(APT)归因框架,利用机器学习的力量来分析CTI报告和其他有用信息,提取有助于归因过程的有价值的特征。
在进行这项研究之前,需要解决一个更基本的问题,即了解特定的CTI报告是讨论哪个特定的APT组织。本文概述了我们自动提取CTI报告所涉及的APT组织的方法,方法是将标准的文档工程技术应用于我们从网络各处收集的CTI报告语料库。这项工作包括多个组成部分,包括采用的方法、数据收集、数据处理技术和实验。最后,我们将讨论所获得的结果,并评估所提方法在准确标记CTI报告方面的有效性。
2 方法
本节阐述了贯穿本研究始终的方法和技术,包括各个阶段。
2.1 数据收集和处理
我们工作的第一步涉及从互联网上的各种来源收集公开可用的CTI报告。共下载了来自207个不同来源的1,000份随机报告,这些报告以各种格式为主要是PDF文档或网页。所有非PDF报告都被转换为PDF文档,以保持一致性并便于进一步分析。表1列出了前5个来源。
表 1:前 5 个 CTI 报告来源以及每个来源下载的报告数量
| Source |
Number of documents |
|
Trend Micro |
62 |
|
Securelist by Kaspersky |
56 |
|
WeLiveSecurity by ESET |
43 |
|
Cisco Talos |
35 |
|
Check Point |
28 |

图 1:数据库中存储的有关每个报告的示例元数据。
2.2 数据处理
第一步涉及使用三个不同的Python库来提取报告的文本,分别是PyMuPDF、PyPDF2和pdftotext。使用各种库是有意为之的,这样可以评估它们相对于我们工作的有效性,并确定哪个库最适合我们的需求并提供最佳性能。
随后,提取的文本存储在数据库中,并输入到一个自定义的spaCy PhraseMatcher中。spaCy是一个功能强大的自然语言处理(NLP)库,提供了一系列功能,如分词、命名实体识别和依赖解析。PhraseMatcher方法允许我们在文档中提取实体或查找特定模式。
PhraseMatcher的内容包括APT组织的名称列表、它们各自的别名以及任何可能的命名约定。例如,apt 1、apt_1、apt-1、apt1。这背后的原因是不同报告对APT的指定可能会有所不同。此外,APT的名称和别名是每次填充PhraseMatcher时从互联网上的各种来源收集的,以确保列表始终保持最新。然后,将PhraseMatcher应用于报告的文本,并返回匹配项列表。这些匹配项的顺序基于它们在文本中被找到的顺序,例如:[apt43, apt43, kimsuky, thallium]。最后,使用Python中collections库的Counter类提取匹配项中最常见的名称。
为了进一步提高APT组织标签方法的准确性,采取了额外的步骤,提取了每份报告的标题。假设报告中的APT组织名称会出现在标题中,因此通过检查spaCy识别出的APT组织名称是否出现在标题中,可以更好地保证准确性。
标题提取过程涉及两种方法:从文档元数据中提取标题或从文档中编写的标题中提取标题,后者通常出现在文档的第一页。使用Python库‘PyMuPDF’从元数据中提取标题,并从第一页提取文档的编写标题。提取报告第一页的段落以及它们的字体大小,然后对文本运行一个自定义函数,以提取具有最大字体大小的短语。一旦标题被提取,它就会存储在数据库中。这种方法是基于通常情况下标题会以较大的字体设置的假设而采用的。使用 NLP 自动标记 CTI 报告.
2.3 报告标签
既然我们有了spaCy提供的APT名称和标题,我们首先验证APT名称是否出现在标题中。然而,由于标题中可能会拼写错误或不完整,因此我们利用Levenshtein字符串距离度量算法进行有效的比较和关联。字符串距离度量是计算两个文本字符串(如名称或短语)之间相似性或差异的计算方法。
如果名称出现在标题中,它将被指定为CTI报告的标签。否则,将使用spaCy提供的名称作为标签。图2展示了整个过程。
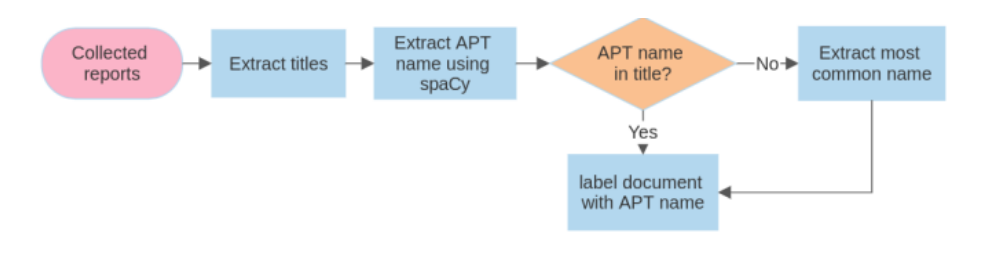
图 2:拟议工作流程图
3 实验结果与评估
为了评估所开发方法的准确性,对每个文档进行了手动标记。这个过程包括阅读和审查每个文档,突出显示文档讨论的APT组,提取标题,最后对整个文档进行分类。手动标记文档使我们更深入地了解了这些文档的性质。从收集的1000份报告中,有947份(94%)是用英语编写的,而其他报告是用中文、日文、乌克兰语、德语和俄语编写的。在英语报告中,有605份报告讨论了单个APT组,28份报告讨论了多个APT组,81份报告讨论了未知组织,其余报告讨论了各种其他主题。在605份报告中提到的190个唯一APT组中,最常提到的APT组包括Lazarus组、APT41、APT29、Magic Hound和Gamaredon组。
由于本工作的目标是标记讨论单个APT组的报告,所有实验和后续的洞见都将基于这605份英文报告。
通过在手动标记过程中手动比较导出的标题与实际报告标题,并突出显示哪些标题是准确的并计算准确性,对标题提取方法的准确性进行了评估。评估结果显示准确性为99%。
随后,进行了使用spaCy方法提取APT名称的几次评估,考虑到我们使用了三个文本提取库。准确性是通过检查spaCy提供的APT名称是否与经过手动验证的APT名称或APT的任何别名相同来衡量的。表2显示了使用最常见的APT名称方法在报告标记中每个库实现的不同准确性,或者通过检查APT名称是否在标题中,或者通过将两者一起应用来实现的准确性。
表 2:每个文库采用不同技术获得的准确度。
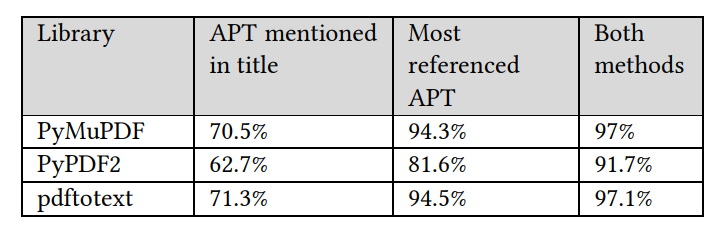
结果表明,PyMuPDF和pdftotext在应用的任何方法中表现相似,其中pdftotext具有最高的准确性,而PyPDF2的性能较差。结果还表明,使用两种方法可以实现最高的准确性。
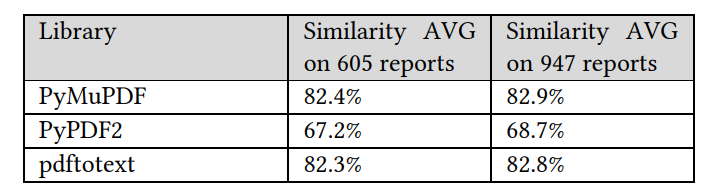
进行了性能差异的彻底分析。根据分析,PyPDF2未能从文档中提取完整的文本,而其他两个库几乎导出了完全相同的文本。使用Sentence Transformers框架计算了每个文档的导出文本之间的余弦相似度,并计算了每个库的平均值。结果表明,PyMuPDF和pdftotext导出了相似的文本,而PyPDF2导出的文本不太相似。此外,通过检查数据集中包括的每份英文报告(947份报告),而不仅仅是这项工作关注的605份报告的内容的相似性,我们可以注意到,即使文档的内容不同,库的性能仍然保持不变。表3显示了在不同报告中每个库实现的相似性平均值。
表 3:不同数量的报告中每个库的余弦相似度平均值。
此外,还计算了每个库提取的文本的平均长度,假设任何库返回的最长长度对应于可获得的最大长度。需要注意的是,由于947份文件是英文文件,因此测试不仅在主要的605份报告上进行,还在其余的文件上进行。我们的分析显示,PyMuPDF和pdftotext提取了几乎相同数量的文本,平均长度为整个文档的99%,而PyPDF2的平均长度为85%。图3展示了在五份不同的CTI报告中每个库提取的文本长度。
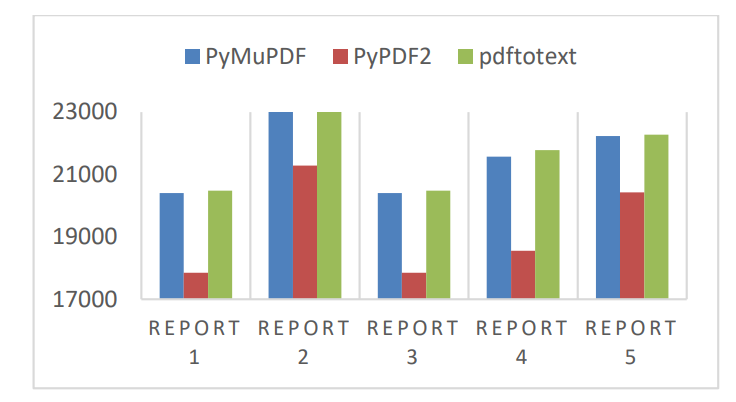
图 3:每个库提取的文档的文本长度
需要强调的是,通过一系列对经过长时间的反复分析的错误标记报告的分析,才达到了所获得的准确性。这个过程使我们能够识别和解决出现的几个挑战,这些挑战包括:
• 文件中的APT可能是未知的,尚未命名。
• 文件中使用的APT名称或别名可能是新的,不包含在数据库或任何公共来源中。
• APT的名称可能是常见的或通用的术语,可能会混淆NLP模型并导致错误标记的报告。
• 文件由扫描的文本(图像)组成。
