推荐博客
Sahiti Kappagantula:https://medium.com/@sahiti.kappagantula
为什么选择数据科学?
有人说数据科学家是“21世纪最性感的工作”。为什么?因为在过去的几年里,公司一直在存储他们的数据。每家公司都在这样做,它突然导致数据爆炸。数据已经成为当今最丰富的东西。
但是,您将如何处理这些数据?
比如说,你有一家生产手机的公司。你发布了你的第一个产品,它大受欢迎。每项技术都有生命,对吧?所以,现在是时候想出一些新的东西了。但是您不知道应该创新什么,以满足用户的期望,他们正在焦急地等待您的下一个版本?
在您的公司中,有人提出了使用用户生成的反馈并选择我们认为用户在下一个版本中期望的东西的想法。
在数据科学中,您应用各种数据挖掘技术,如情感分析等,并获得所需的结果。不仅如此,您可以做出更好的决策,您可以通过高效的方式降低生产成本,并为您的客户提供他们真正想要的东西!
有了这个,数据科学可以带来无数的好处,因此你的公司绝对有必要拥有一个数据科学团队。
什么是数据科学?
随着数理统计和数据分析的发展,最近出现了数据科学一词。这段旅程令人惊叹,我们今天在数据科学领域取得了如此多的成就。
在接下来的几年里,我们将能够像麻省理工学院的研究人员所声称的那样预测未来。凭借出色的研究,他们已经在预测未来方面达到了一个里程碑。他们现在可以用他们的机器预测电影的下一个场景会发生什么!
数据科学,它也被称为数据驱动科学,它利用科学的方法、过程和系统从各种形式的数据中提取知识或见解,即结构化或非结构化。
这些方法和过程是什么???
谁是数据科学家?

正如您在图片中看到的,数据科学家是所有行业的大师!他应该精通数学,他应该在商业领域取得领先,并且还应该具有出色的计算机科学技能。害怕的?不要。虽然你需要在所有这些领域都表现出色,但即使你不是,你并不孤单!
没有“完整的数据科学家”这样的东西。如果我们谈论在企业环境中工作,工作是分布在团队之间的,每个团队都有自己的专长。但问题是,你应该至少精通其中一个领域。此外,即使这些技能对您来说是新技能,也要冷静!这可能需要时间,但这些技能是可以培养的,相信我,花时间投资是值得的。为什么?好吧,让我们看看就业趋势。
数据科学家工作趋势
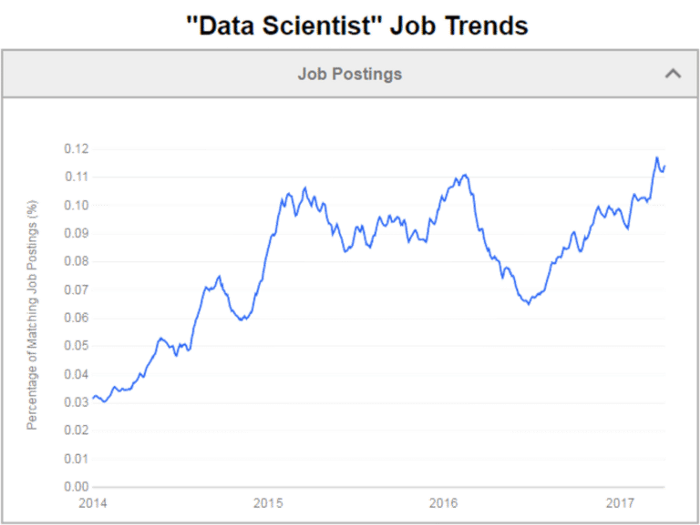
图表说明了一切,数据科学家不仅有很多职位空缺,而且这些职位的薪水也很高!
我们现在知道,学习数据科学实际上是有道理的,不仅因为它非常有用,而且你在不久的将来也会有一个伟大的职业生涯。
如何解决数据科学中的问题?
数据科学中的问题是使用算法解决的。但是,最重要的判断是使用哪种算法以及何时使用它?
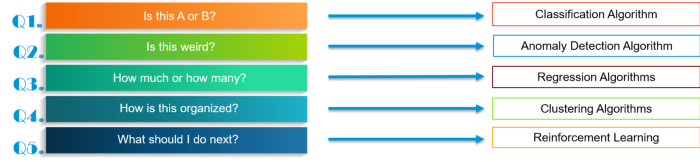
基本上,您在数据科学中可能会面临 5 种问题。
- A还是B得问题? —> 分类算法
- 这是奇怪的么? —> 异常检测算法
- 多少的问题? —> 回归算法
- 如何组织的? —> 聚类算法
- 接下来做什么 —> 强化学习
问题1:这是A还是B?
对于这个问题,我们指的是具有明确答案的问题,例如在具有固定解决方案的问题中,答案可以是是或否、1 或 0、感兴趣、可能或不感兴趣。
当我们只有两种类型的答案,即是或否,1 或 0 时,称为 2类别分类。有两个以上的选项,称为多类分类。
问题2:这个奇怪么?
看下图,发现了红人!

每当模式出现中断时,算法都会标记该特定事件供我们查看。信用卡公司已经实施了该算法的实际应用,其中用户的任何异常交易都被标记以供审查。从而实现安全并减少人类的监视工作。
问题3:多少的问题?
比如:明天的温度是多少?
由于我们期望在对这个问题的响应中有一个数值,因此我们将使用回归算法来解决它。
问题4:这是如何组织?
假设您有一些数据,现在您不知道如何从这些数据中获得价值。因此,问题是,这是如何组织的?这该如何组织?
您可以使用聚类算法来解决它!!!

聚类算法根据常见的特征对数据进行分组。例如在上图中,点是根据颜色组织的。同样,无论是任何数据,聚类算法都试图理解它们之间的共同点,从而将它们“聚类”在一起。
问题5:接下来做什么?
每当您遇到问题时,您的计算机必须根据您对其进行的训练做出决定,这涉及到强化算法。
例如:
您的温度控制系统,当它必须决定是降低房间温度还是提高房间温度时。
这些算法是如何工作的?
与其教计算机做什么,不如让它决定做什么,在动作结束时,你给出正面或负面的反馈。因此,与其定义系统中的正确与错误,不如让系统“决定”做什么,并最终给出反馈。
这就像训练你的狗一样。你无法控制你的狗做什么,对吧?但是当他做错事时,你可以责骂他。同样,当他做预期的事情时,也许会拍拍他的背。
让我们把这个理解应用到上面的例子中,假设你正在训练温度控制系统。房间里的人数增加,系统必须采取行动。要么降低温度,要么提高温度。由于我们的系统什么都不理解,它需要一个随机的决定,假设它会增加温度。因此,您给出了负面反馈。有了这个,计算机就会知道房间里的人数增加时,永远不会增加温度。
同样,对于其他操作,您应给予反馈。对于每个反馈,您的系统都在学习,因此在下一个决策中变得更加准确,这种类型的学习称为强化学习。
什么是机器学习?
它是一种人工智能,使计算机能够自行学习,即无需明确编程。通过机器学习,机器可以在遇到新情况时更新自己的代码。
我们现在知道数据科学得到了机器学习及其分析算法的支持。我们如何进行分析,我们在哪里进行分析。数据科学还有一些组件可以帮助我们解决所有这些问题。
在此之前,让我回答一下麻省理工学院如何预测未来,因为我认为你们现在可能能够将其联系起来。因此,麻省理工学院的研究人员用电影训练了他们的模型,计算机学习了人类的反应,或者他们在采取行动之前如何行动。
例如,当你要与某人握手时,你会把手从口袋里拿出来,或者靠在对方身上。基本上,我们所做的每一件事都有一个“预先行动”。计算机在电影的帮助下接受了这些“预动作”的训练。通过观察越来越多的电影,他们的计算机能够预测角色的下一步行动。
数据科学组件
1. 数据集
你会分析什么?数据,对吧?您需要大量可以分析的数据,这些数据被提供给您的算法或分析工具。您从过去进行的各种研究中获得这些数据。
2. R Studio
R 是由 R 基金会支持的用于统计计算和图形的开源编程语言和软件环境。
3. 大数据
大数据是数据集的集合,它如此庞大和复杂,以至于使用现有的数据库管理工具或传统的数据处理应用程序变得难以处理。
现在要驯服这些数据,我们必须想出一个工具,因为没有传统的软件可以处理这种数据,因此我们想出了 Hadoop。
4. Hadoop
Hadoop 是一个框架,可帮助我们以并行和分布式方式存储和处理大型数据集。
5. Spark R
它是一个 R 包,提供了一种将 Apache Spark 与 R 结合使用的轻量级方式。
